
Bare-bones search request
Abstract
This document discusses the Generic Interoperability Framework in context of the DLI2 project. We demonstrate how the goals and technologies envisaged in the Stanford InterLib Project can be leverages using this framework.
| Interface Description | Mixing, partial understanding, separability | Extensibility | Ease of use | Footprint | |
| Generic Interoperability Framework | ++ | ++ | ++ | ? | + |
| CORBA/IIOP | + | - | + | -/o | - |
| CGI/HTTP | -- | - | o | +/o | + |
Extensibility is a particularly strong feature of our framework. Crucial characteristics include support for mixing and partial understanding. To illustrate, consider search in digital library repositories. This is a vital example, since some kind of agreement is needed to allow diverse digital libraries resources like document collections, image repositories etc. to interoperate. A search interface proposal for digital libraries has been presented with SDLIP (Simple Digital Library Interoperability Protocol). According to this proposal a search method synchronously invoked on a DL repository has the following description in CORBA/IDL:
Void searchSynch(
Long clientSID,
// Client-side session ID (unique within client)
String subcols,
// Choice of collections to search w/in LSP
String queryLang,
// Query language used for the query
String query,
// The query
Long numDocs,
// Number of documents to return (-1: all)
String[] docProps, //
Properties to return for each result document
// (e.g. ['Abstract', 'Title', ...])
Long stateTimeoutReq, // Request for number
of seconds to
// maintain state at server. -1: request unlimited time
PropList queryOptions, // Additional info for
the LSP
OUT Long stateTimeout, // Time server is willing
to maintain state
OUT Long serverSID, // ID
by which server identifies this session
OUT ResultAccess serverDelegate, // Delegate followup requests
OUT SearchResult result // XML-encoded result list.
)
This search request realizes both the core search function, the state maintainance and the load balancing between client and server. Query scope is given in subcols argument, the query parameter contains the query expressed in queryLang. docProps specifies the properties of documents to be returned as result, whereas numDocs gives the maximal size of the result set. Using queryOptions additional query options are submitted. Principally, the core search could presented as follows:
Void searchSynch(
String subcols,
// Choice of collections to search w/in LSP
String queryLang,
// Query language used for the query
String query,
// The query
Long numDocs,
// Number of documents to return (-1: all)
String[] docProps, //
Properties to return for each result document
// (e.g. ['Abstract', 'Title', ...])
PropList queryOptions, // Additional info for
the LSP
OUT SearchResult result // XML-encoded result list.
)
The state maintainance interface part is:
Long clientSID,
// Client-side session ID (unique within client)
Long stateTimeoutReq, // Request for number
of seconds to
// maintain state at server. -1: request unlimited time
OUT Long stateTimeout, // Time server is willing
to maintain state
OUT Long serverSID, // ID
by which server identifies this session
Load balancing is achieved in original interface by telling the client to send all further requests to serverDelegate. Load balancing interface part consists therefore just of a single return parameter
OUT ResultAccess serverDelegate, // Delegate followup requests
A number of issues come up to mind when looking at this interface decomposition. First of all, combining three different functions in a single interface does not seem elegant. On the other hand, creating three separate interfaces would require three calls to achieve the same result. The original interface chosen presents a balance between modularity and efficiency. One can imagine the search request taking place within a secure context as a not far-fetched possible extension. In this case, an additional authentication handle would have to be transmitted along the search query. Interface extension would be needed to integrate this functionality.
In contrast, some simple applications would never ever make use of the queryLang or docProps parameters. Would is be adequate to start with some bare-bones search interface having just one parameter for the search query? The root of the problem lies in the rigid interfaces of distributed computing. They do excellent job providing well-know fixed interfaces. However, they do not address evolvability of interfaces appropriately (for example, it is not possible to establish a relationship between two CORBA/IDL interfaces). Neither do simple solutions like HTTP/CGI, which provides no interface descriptions at all.
Apparently, it would be desirable to have a more flexible interface allowing simple applications make simple calls, whereas more complex applications could use advanced features. Individual digital library may want to provide additional search facetts without breaking the basic interface. Furthermore, evolution of server or client interfaces should require no changes in their counterparts. Below we demonstrate an example, how an extendable search interface could be incrementally designed using the Generic Interoperability Framework.
Let us start with bare bones. The fundamental information needed to start a search is the search query. Thus, our first search request for "color printers" could have the following generic representation:
Bare-bones search request
Now assume we realize that result set limit, collections to search and query language specification used would be also useful parameters. A search request in the Computer Science Technical Reports (CS-TR) collection stated in a Boolean and returning maximum 10 documents could be formulated as presented in (Fig). Default values can be used if these parameters are omitted, as in bare-bones request.
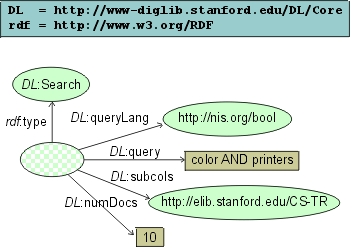
More specific request
Imagine now that some other digital repository, for example at Santa Barbara, requires explicit state maintainance support in order to provide access to their repository in a more efficient way. This can be achieved by adding two new properties to the original search request like depicted below. Digital repositories not supporting state maintainance ignore these properties and follow their own implicit strategies. Client not aware of state maintainance features at Santa Barbara can still query the repository.
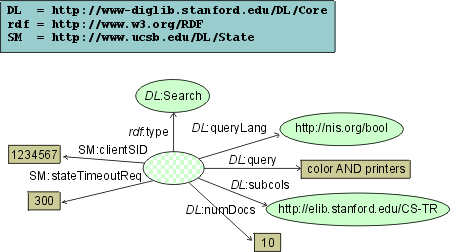
Adding state maintainance support
Load balancing support can be provided in an analogous fashion attaching new property to the search result return by the digital library collection. The Generic Interoperability Framework provides two powerful interface feature: mixing and partial understanding. Mixing allows to combine complex repository interface using generic modules or layers. For example, reliability and security layers can be added to the core search interface to provide perpetual activity services and secure workflows.
Imagine that our digital repository decides to bill for its services. The billing is carried out using authentication information provided along with the search request. Two main challenges are:
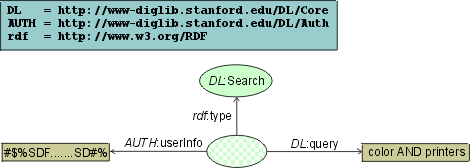
Request containing authentication information (simplified)
If, however, some client tries to access the repository through the "old" interface without authentication information, an error message is returned to the client (Fig). It is essential that the error message delivers enough information for the client to learn about interface changes.
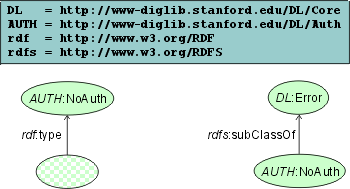
Error message for not authenticated clients / schema information
In the series of examples above we demonstrated how extensible interfaces can be build within our framework. We used the example of a search interface. Similar approach can be applied for other services like summarization, authentication, resource discovery etc. In fact, all of the semantics of a digital repository can be encapsulated within the framework. In particular, it is also suitable for description and realization of interfaces to dynamic artifacts like mobile code. This can be done in the same way how the digital library components themselves are described.
Layered architecture of the Generic Interoperability Framework is strictly more powerful than CORBA or COM objects equipped with multiple interfaces. A "method call" across two separate interfaces can be accomplished in our framework using a single invocation whereas in CORBA or COM multiple invocations needed to achieve the same effect. Moreover, generic reusable layers (e.g. security, monitoring, load balancing) can be developed minimizing reimplementation effort needed to equip existent services with new functionality. This is done by filtering requests and replies of components through these generic layers.
Design of a workflow protocol allowing for secure billing for services would face major difficulties using conventional technologies. In particular, intertwining library operations (e.g. search, merge results) with the security actions (e.g. watermark documents, payment) would lead to protocols which are hard to understand and to maintain. Using layers and separation techniques provided by the Generic Interoperability Framework it is possible to achieve clean separation between orthogonal interfaces like core digital library and payment. Furthermore, our framework provides illustrative easy-to-understand protocol descriptions.
Consider the authentication examples (Fig) of the previous section. Similar approach can be used to transparently require authentication from the client using library services. Authentication and payment requests are carried out by the intermediate security layer residing between the core library services and the client. On receiving unauthenticated request, the security layer asks client to provide authentication information delaying access to the core services. The security layer, or any other intermediate layer, may perform a number of interactions with the client before the original request gets to the destination layer.
Consider the following simplified example of a system interconnecting four main components
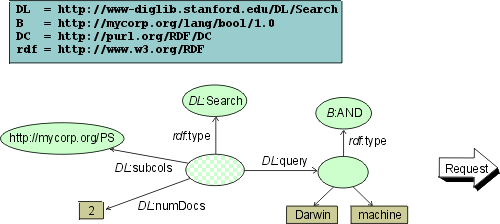
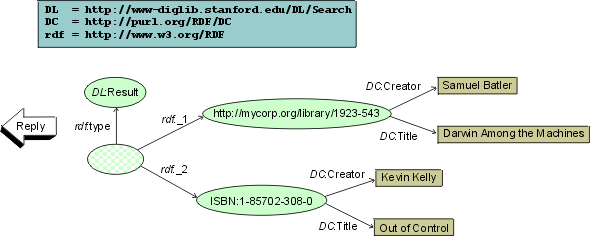
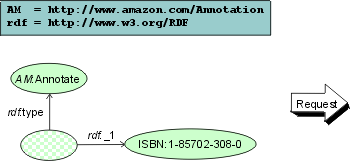
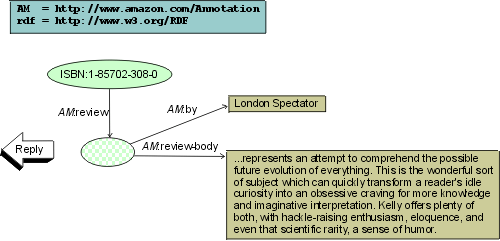
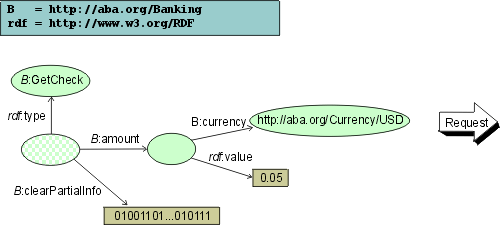
The client's security layer replies (transparently for the core service) with the check data:
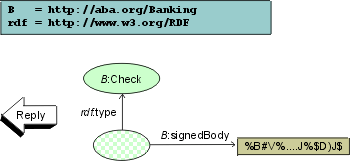
The security layer of the annotation service consults the bank and cashes the check:
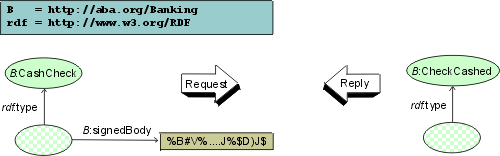
Afterwards, the original annotation request is processed by the core
annotation service. The security layer described above can be used for
billing for library search in analogous fashion. The layered architecture
described provides an elegant way of mixing complex digital library interfaces.