Working Paper
(under construction)
Generic Interoperability Framework (GINF) Middleware
Describing the "Magic"
Sergey Melnik et al.
Department of Computer Science,
Stanford University
melnik@db.stanford.edu
Abstract
This document discusses an implementation of the Generic Interoperability
Framework. It describes in detail how software components exchange and
process messages represented as RDF models and how schema information is
fetched and evaluated. We also present an API and guidelines for application
programmers.
Introduction
The goal of the Generic Interoperability Framework (GINF) is to facilitate
interoperability between heterogeneous systems [1].
GINF is a set of principles which describe an application-neutral way of
interaction between software components. The key principles include:
-
Generic representation: protocol information, languages, data and interface
descriptions are represented in a uniform manner using directed labeled
graphs.
-
The ability to dynamically fetch a machine-readable description for every
piece of information exchanged between components.
This document describes a realization of this principles which provides
semantic-oriented middleware for application development and integration.
Our intension is to address the spirit of "magic" perceptible in the introductory
paper [1]. We will show how the components
discover each other's interfaces on-the-fly, which tasks are performed
automatically by the middleware, which advantages become available for
the application developer and in which direction the complexity is shifted.
We will also point out the limitations of the current implementation and
show how they can be addressed.
First, we give a brief overview of the GINF middleware. Afterwards we
describe application development using this middleware. Finally, we demonstrate
a comprehensive show case using an application which implements multicast
streaming of prefetched Web pages.
Overview
Middleware is referred to as an application-independent software that enables
the application developer to concentrate on implementing the core functionality
of the application without being concerned with some common tasks like
networking, windowing, etc. In GINF components exchange messages that are
encoded as RDF models and contain data, language and protocol information.
The tasks covered by the GINF middleware include:
-
Message transport over the network
-
Parsing of messages encoded in RDF/XML into an graph model
-
Serialization of the graph model into RDF/XML messages
-
Implementation of an API for the manipulation of the graph model
-
RDF schema management, automatic retrieval of schemas for unknown elements
-
Evaluation of schema information:
-
computing transitive closures of rdfs:subPropertyOf and rdfs:subClassOf
properties
-
evaluation of rdf:type (instance of) property using class hierarchy
The figure below represents the key components of the architecture and
summarizes
their functions:
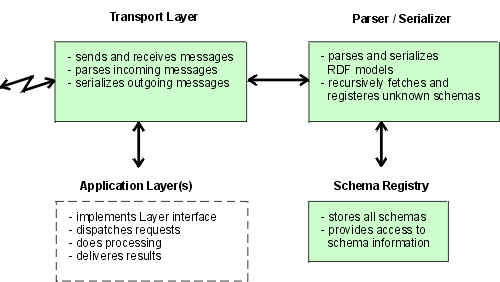
Since the application-specific protocol information is contained withing
the messages exchanged between components, the choice of the transport
layer is not essential. Currently, we specified an HTTP and a TCP/IP mapping
for the basic communication protocol. Note that other mappings (e.g. to
CORBA/IIOP, E-Mail) and delivery principles (e.g. connectionless transport)
are also possible.
In the following discussion we refer to the HTTP mapping of the basic
communication protocol. The sequence of the tasks performed on the "server-side"
include:
-
listening on a socket
-
receiving communication request, establishing a connection
-
reading a serialized model from the connection
-
calling the parser, which performes the following operations:
-
it examines the model, determines unknown schema elements and calls itself
recursively to fetch all unknown schemas,
-
registeres all new schemas with the Schema Registry,
-
returns a graph representation of the model
-
calling the application layer to dispatch the model (afterwards application
transparently accesses the schema information)
The GINF middleware implementation we describe in following sections defines
abstract interfaces for the Parser/Serializer (RDFMS), Schema Registry
(SchemaRegistry), graph model (Model) and schema-aware graph
model (SchemaModel). Besides that default Java implementations of
every interface are provided. The default implementations can be overridden
in order to provide a more efficient realization or extend the functionality
of the system.
Application Design
This section describes the basic steps of application development using
GINF middleware. These steps are summarized below:
-
Description of the semantics of the application interface in an RDF schema
(or a set of RDF schemas). The schema contains descriptions of protocol,
language and data elements used in the application. As many application-specific
concepts as possible should be derived from existing ontologies.
-
(Optional) Compilation of Java interfaces to schema elements. These interfaces
allow to programmatically refer to the vocabulary described in the RDF
schema and to load schema information directly from Java classes rather
than over the network. The compiler is provided.
-
Implementation of the application logic.
In following we will go through these steps in more detail.
Step 1: Interface definition
General considerations
Interface definition is a crucial step in which much care and insight should
be invested. This step can be considered as the specification phase of
the application development. The behavior and evolvability of the application
are determined to a high degree here. We cannot hope to ever be able to
perform this step automatically since no automated tool can determine the
purpose of a new application. Comprehensive GUI tools could, however, be
helpful.
The idea of extensible and interoperable components is based on the
premise that they can dynamically learn about each other's capabilities
by fetching and evaluating the corresponding interface descriptions, or
semantic schemas. A semantic schema is a document, real or imagined, which
defines the inferences from one schema to another, thus defining the semantics
of one syntactic schema in terms of another [2].
A computer may have "built-in" knowledge of concepts like "zip code" or
"search request" defined in terms of operations it can perform on them.
Such predefined semantics is either hard-coded into the application or
can be downloaded as mobile code. The primary source of knowledge contained
in a schema definition are the relationships between schemas. Therefore,
it is important to reuse existing schemas and to define schemas in a reusable
way rather than to build every application from scratch.
According to the guidelines of the RDF specification we assume that
a schema cannot be changed. The same is true for the semantics of the concepts
defined in a schema; once a globally unique concept like "5-digit zip code"
is defined in a particular schema, its meaning can be regarded as frozen.
Applications that have built-in knowledge of this particular zip code do
not need its description any more. If the notion of a 5-digit zip code
is to be extended, specialized or given some other schades of semantics,
its definition must be placed in another schema. However, both concepts
can refer to each other, e.g. a "5-digit zip code" is-a "7-digit
zip code".
Learning from schema descriptions
A schema contains descriptions of elements, or resources, used in messages
exchanged between components. A schema specifies additional properties
of these elements. Like the messages themselves, a schema is represented
as a valid RDF model. Schema information is not explicitly sent to the
components. Rather, it can be fetched by a component if needed. GINF middleware
retrieves schemas automatically once it encounteres previously unknown
elements. A "bootstrapping" vocabulary has been defined within the RDF
effort which specifies the key concepts, like instantiation and subclassing,
usable in establishing relationships between elements.
Example:
consider a component receiving a message. The message contains (among
other descriptions) the following information:
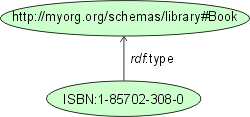
The property rdf:type is a "bootstrapping" concept which specifies
the basic typing mechanism. One could also think of it as class instantiation,
similar to the notions instance-of or is-a used in object-oriented
systems. Upon discovering the above statement, GINF middleware concludes
that the element (resource) identified by its ISBN number is an instance
of some given class and therefore must have all properties that every member
of this class possesses. Thus, we can learn more about the given instance
by discovering the properties of the class it belongs to. The description
of the class http://myorg.org/schemas/library#Book is available
at the URL of the same name. For example, we might find out by fetching
the schema description that a Book may have bibliographic attributes;
we may also discover that Book is a subclass of LibraryItem:

This information implies that a Book is usable in every context
where a LibraryItem can be used.
There are tight limitations with respect to what a piece of software can
"learn" using only the basic typing and subclassing vocabulary. In general,
to meaningfully process some new concept B the component must have
built-in knowledge of the concept A from which B was derived.
For the sake of simplicity we leave aside AI approaches which would allow
to determine the meaning of B from the context where it is used.
Even with this simple means it is possible to design applications which
are extensible in a well-defined way. The extensibility is reinforced by
a coherent modeling of data, languages and protocols. An application may
react in three possible ways upon encountering an unknown concept or element:
-
Ignore
Example: the transport layer which is responsible for the message
delivery between components doesn't care where the message it forwards
is a SuccessfulReply or an Error as long as both are derived
from Message.
-
Warning
Example: a digital library search server may still meaningfully
process a search request containing unknown search constraints issuing
a warning that a result set to be delivered is larger than requested due
to unsupported constraints.
-
Error
Example: a financial application will return an error if it
does not recognize the currency noted on the check.
Apparently, mechanisms reaching far beyond the basic typing and subclassing
are needed if we want to describe more sophisticated behavior. Fortunately,
vocabulary used in schema descriptions is not limited in any way. Thus
dedicated vocabularies can be developed allowing to describe subtle differences
in application interfaces and behavior. Having rich interface specifications
facilitates automatic translation of procotols, languages and data between
heterogeneous components. For example, having a protocol specified as a
finite state machine would allow to automatically generate stubs conforming
to the protocol. State automata could also be used to describe protocol
translation. Clearly, built-in knowledge of state machine concepts like
Event,
Action and StateTransition would be required in order to
process this kind of schema information. Currently we are investigating
how rich vocabularies can be used for automatic protocol translation and
other schema descriptions.
Predefined schemas
Common built-in knowledge is required for the components to interact meaningfully.
For example, an application should be able to tell the transport layer
to deliver a message to some other component. Both the application and
the transport layer must agree on some set of concepts e.g. what a message
is, where it should be delivered etc. For this purpose we defined a core
communication ontology [3]. Its main goal
is to enable the components to identify a Message, to tell whether
it is a Request or a Reply and to identify the delivery information
attached to a message.
The HTTP layer is a connection-oriented transport layer. Therefore,
we defined a core state ontology which is intended to serve as an abstraction
of a connection-oriented communication [4].
This schema defines the concept of "state information" that can be attached
to a message. The HTTP layer defines the notion of an "HTTP connection"
that can be passed along with the message to specify, for example, via
which outgoing connection the message should be sent. Note that even the
basic transport layers --- HTTP and TCP/IP layer --- do not provide an
API in a traditional sense. Rather, their interfaces are described within
the framework.
Designing a new schema
This section provides some informal guidelines for the design of new schemas.
First of all, you have to decide under which URL the schema is to be
stored. If you anticipate multiple and/or evolving schemas it is advisable
to use URLs of the form:
http://yourDomain/yourPath/1999/06/18-your-schema-name
For example, the "core communication" schema mentioned above is stored
under
http://www-diglib.stanford.edu/diglib/ginf/1999/05/26-core-comm
Let us discuss
Next you have to
Step 2: Schema interface generator (optional)
Implementation of the application logic
As mentioned above, the middleware shields the developer of networking,
parsing and schema management issues. The only interfaces that the developer
should use are the Layer and the Model interface.
The Layer interface
Show Case: WebBase Streaming Facility
References