Abstract
This paper presents the Generic Interoperability Framework developed to facilitate integration of heterogeneous information systems. We propose a universal interface which avoids common models and languages. Within our framework individual communication protocols, data manipulation languages and data are represented in a generic manner preserving their ontological variety. We describe how a mediation infrastructure can be built using canonical wrappers. To address operational requirements of integration we suggest a layered architecture for component design. The key concepts of the framework are demonstrated using examples taken from Digital Libraries.Keywords: interoperability, heterogeneous systems, mediation, digital libraries, RDF
From the system perspective, the major sources of heterogeneity include disparate communication protocols, incompatible data manipulation languages and conflicting data representation. Different interoperability levels can be distinguished with respect to each system dimension: syntaxt, structure and semantics. Integration tasks can be arranged along these two dimensions forming a heterogeneity matrix depicted in (Fig). The examples should chiefly serve for illustration purposes, since the differences between syntax, structure and semantics are not always clear [PCGM+98]. Furthermore, protocols, languages and data may depend on each other (e.g. JDBC, SQL and the relational model) or may be combined (wrapped) within a single interface (e.g. using CORBA/IDL).
|
|
|
|
||
| Protocols | IIOP vs. KQML vs. HTTP message encoding | synchronous vs. asynchronous; stateful vs. stateless | transactions; payment | ||
| Data Manipulation Languages | SQL DML vs. OQL | declarative vs. procedural | transitive closure; "knows" operator | ||
| Data / Metadata | XML vs. ASN.1 | relational vs. object-oriented | circle as (center, radius) vs. (point1, point2, point3) |
Goal A significant long-term goal for information integration is complete independence of protocols, languages, data models and formats [PCGM+98]. This vision suggests a possibility to dynamically discover the functionality of online components and to engage in interaction with components using a uniform interface. Important is the ability to utilize a variety of components with only minimal requirements on their interfaces [Wie92].
Subject of the paper To address the above
mentioned issues we suggest a generic
(rather than common) interface used between interacting components. As
noticed in [CDSS98], one can easily map anything
into a tree or graph structure. In previous approaches, the interpretation
of "anything" was mainly limited to diverse data structures. In our work
we propose to extend generic representation to additionally cover communication
protocols and data manipulation languages used in heterogeneous systems.
By the term "generic" we mean that the semantics of protocols, languages
and data remain preserved. Instead of choosing a common model and language
which are required to be supported by all components of a mediation architecture,
individual protocols, languages and data are transformed into a generic
representation retaining their ontological variety. This allows to reduce
heterogeneity issues arising upon integration to semantic heterogeneity.
Preserving semantics of component interfaces increases the autonomy
of wrappers since they are not forced to support common models and languages.
Besides that, the generic representation of domain-specific source interfaces
can be achieved in a canonical manner which simplifies the design of wrappers.
Canonical wrappers choose a generic
representation of protocols, languages and data which requires minimal
translation effort. Shifting translation to mediators puts additional complexity
into them. Therefore, providing automated,
specification-based mediation is crucial. In order to to make integration
practicable, we suggest reconciliation on
the instance level as opposed to the schema level. That means, the components
directly exchange generically represented messages carrying protocol, language
and data information. Still, to facilitate specification-based mediation,
a generic representation should provide access to the description of the
semantics and structure of all data and operations (e.g. using metadata,
ontologies etc. [KS97]).
Outline of the paper This paper is organized as follows. Next section addresses some essential characteristics of universal interfaces. In (Sec) we show how the generic representation of protocols, languages and data is accomplished within our framework. The mediation infrastructure that we envisage is presented in (Sec). (Sec) introduces a layered architecture for system components. After examining related work in (Sec), we conclude the paper (Sec) and address future directions.
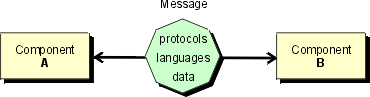
"The network is the least structured organization that can be said to have any structure at all."This section presents our approach to a universal interface that can be used in a mediation infrastructure. Noting that anything can be easily mapped into a graph, we propose mapping the whole model of component's interaction into a generic graph representation. This includes protocols, languages and data used by the component. The mapping is performed on the instance level. Thus, a message containing protocol, language and data information (see Fig) is suitable for direct exchange between components2*.
--- Kevin Kelly, Out of Control
RDF Directed labeled graphs represented
in RDF are referred to as RDF models. An edge of the graph represents a
predicate that holds between a subject node and an object node. Two types
of nodes are distinguished: resources and literals. Resources represent
entities that can be specified using a Uniform Resource Identifier (URI).
Hence, any identifiable entity (e.g. book, person, database object) can
be represented by a resource. String or binary data are described using
literals. Every node or edge label belongs to a namespace. Namespace URIs
can be used to lookup meta (schema) information describing elements used
in the graph structure. Schema data itself is represented as an RDF model.
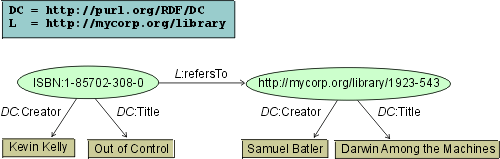
The example below depicts two resources
(ovals with URIs inside) denoting publications. Each of them has two bibliographic
attributes (literals), author and title, identified using the DublinCore
vocabulary. The shortcuts DC and L expand
to the corresponding namespaces where the maschine-readable schema information
for the graph instances can be retrieved.
RDF models are serialized using XML. The discussion of this paper requires only basic understanding of the Resource Description Framework. As we proceed, further RDF features will be explained where they are essential for the understanding of examples. Comprehensive specification of this open standard can be found in [RDF99].
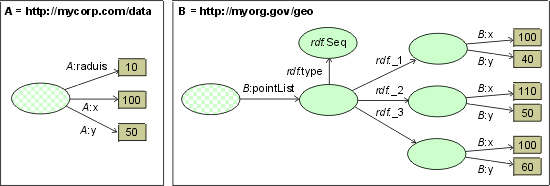
Data There is a significant difference between a common model and a generic representation that preserves application-specific or domain-specific ontology. Consider, for example, a concept "circle" used in two heterogeneous information systems. One of the systems is a relational database (A) where circles are stored as tuples (X, Y, radius). The other is an object-oriented database system (B) containing objects that represent circles using a list of three points. Each "point" object has two attributes specifying its X and Y coordinates. (Fig) shows two generic representations of a circle instance. There is no common model behind these representations. Specific ontological structures of both models are preserved. Thus, the concept "point" is kept in (B) whereas no additional point notion needs to be introduced in (A).
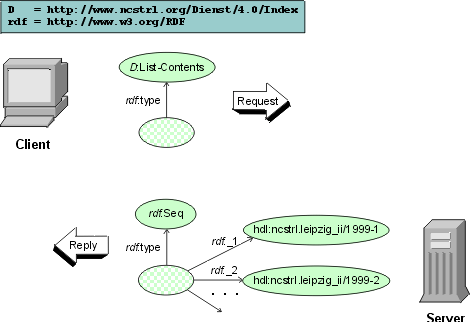
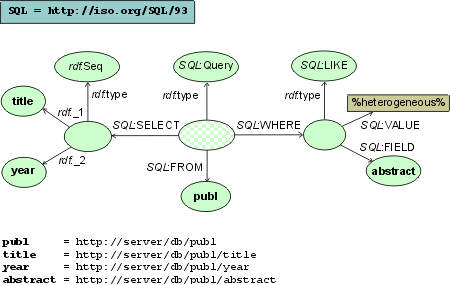
Protocols In addition to data, a message (i.e. RDF model) exchanged between components contains protocol and language information . Above, two examples of data representation were given. (Fig) below shows how a simple request and reply can be modeled using generic representation. This example is based on the Dienst protocol employed in the NCSTRL architecture [Le98]. On receiving the List-Contents request the server sends back a complete list of documents indexed at the collection.
SELECT title,year FROM publ WHERE abstract LIKE '%heterogeneous%'
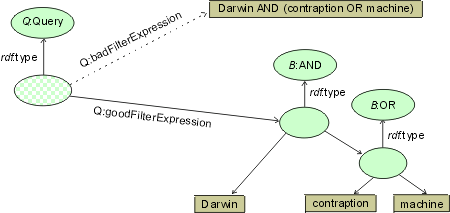
Without parsing the query the component is not even able to find out whether the server-side objects referenced in the query (e.g. the table publ and the field publ.title) in fact exist. Query routing is a heavily used technique in federated systems [AKH96, BBB+97]. However, both implementation of parsing modules and actual computation of query structure are costly. To avoid this overhead, queries in InfoBus [PBC+99], for example, are parsed by the client and transmitted to the server(s) in a structured form. Our framework requires all objects including those "hidden" in queries to be easily identifiable, i.e. queries to be prepared in a transparent structured form, not as opaque strings. At first sight, this requirement puts additional complexity into clients. As end-user query languages are increasingly interfaced by graphical query construction tools, this difficulty gradually disappears. (Fig) compares two ways of representing a filter expression in a search query. One of them is a literal containing a boolean expression coded according to some specific syntax. The second (preferred) representation decomposes the opaque expression into atomic elements.
Mixing Protocol, language and data information can be flexibly mixed within a graph structure. Information pieces enclosed in an RDF model can be identified using namespaces. Looking at an RDF model, a component can easily recognize edges and nodes belonging to a certain namespace. In this manner, relevant information pieces can be processed and irrelevant can be ignored. Thus, mixing and partial understanding of component messages can be realized through a combination of namespaces in a graph structure.
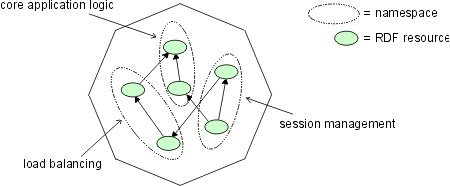
Figure (Fig) depicts an example of a message transferred between two Digital Library systems. It contains RDF resources pertaining to three namespaces: core application logic, session management and load balancing. It is possible to first implement the core application logic and then to add missing functions incrementally using a modular layered architecture discussed in (Sec). In this way, modularity and evolvability of the system can be improved.
To make the mediation task manageable, so-called wrappers are placed between mediators and information (re)sources. Wrappers shield mediators from some aspects of heterogeneity inherent in information souces. Task distribution between wrappers and mediators can be organized in different ways. The decision to be made is which part of heterogeneity has to be hidden from mediators. Wrapper design requires profound knowledge of the native interface of a component. Hence, wrappers often have to be written by the component's vendors. Therefore, it is crucial to simplify wrapper design by putting only minimal requirements on their interfaces [RS97].
Canonical wrapper Bearing this requirement in mind, task separation between wrappers and mediators in our framework is achieved in the following way. Wrappers provide uniform interface to components using generic representation of their protocols, languages and data as described in (Sec). We call such wrappers canonical. Canonical wrappers have no commitment to common data models and languages. Moreover, their design and implementation can be carried out in a relatively straight-forward way. Canonical wrappers are not required to provide capabilities reaching beyond that of components they serve. In particular, they do not need to perform postprocessing of queries, join calculations, provide transaction or security context etc. Roughly speaking, canonical wrappers deal with syntactic heterogeneity aspects of protocols, languages and data whereas mediators tackle semantic heterogeneity.
Let us consider a simple example of how a canonical wrapper can be constructed out of a given interface description. Assume, MyCorp Inc. offers a digital library service for a number of repositories including a collection on Popular Science (PS). The search interface to the library is described as follows in CORBA/IDL:
struct BibRec {
String handle;
String title;
String creator;
};
typedef sequence<BibRec> BibRecList;
BibRecList search(in String collection, in String query, in long limit);
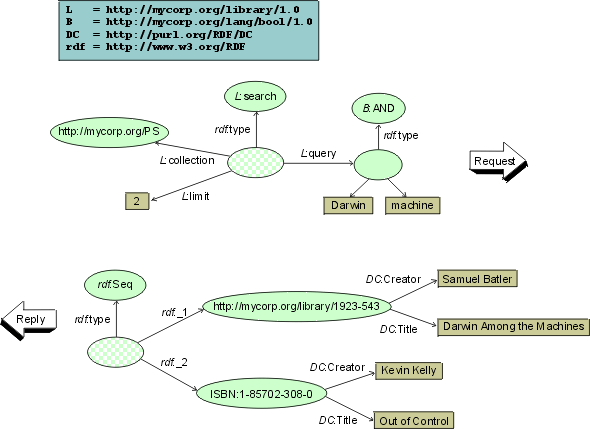
This search interface combines protocol, language and data characteristics. The library is accessed via synchronous calls (protocol feature) submitting a query (language feature) which return bibliographic fields of found items (data feature). The search method is called with three parameters: a collection identifier, a query expressed in a fixed query language and the maximal number of results to deliver. Assume, a search request
search("PS", "Darwin AND machine", 2)
returns a list of two structures:
{ ("ISBN 1-85702-308-0", "Out of Control", "Kevin Kelly"),
("MYCORP 1923-543", "Darwin Among the Machines", "Samuel
Batler") }
(Fig) demonstrates a possible generic
representation of this interaction as interfaced by a canonical wrapper.
The collection identifier ("PS") is not represented as a literal but rather
as a resource meeting the requirement of identifiability of persistent
objects. The search query is decomposed in a structured representation,
too. The "handle" attribute of digital objects returned by the library
service is not needed any more since it is replaced by the corresponding
resources.
Using generic representation only a minimal translation effort by the wrapper is required. Chiefly, it maps data structures between the native and the generic representation and recomposes language expressions into a string. Since the generic representation can be freely chosen by wrapper designer, it can be optimized to perform data structure mapping efficiently. Although recomposition of language expressions introduces some additional work, it can significantly simplify translation done by mediators. Besides that, structured language expressions can be preprocessed by the wrapper. For example, it can make sure the component gets a query which does not contain unsupported or forbidden operator combinations3*. Generally, making string out of structure is much easier than the other way round.
It is essential that a wrapper can be written from scratch on any platform
using only some basic lightweight programming libraries. High complexity
and cost of mediation environment may negatively influence scalability
and acceptance of the mediation infrastructure [PBC+99].
Basically, a canonical wrapper requires only an RDF processing module.
Such module is typically based on simple XML parser and provides a graph
manipulation API [SiRPAC].
Mediator Simplifying wrappers necessarily
complicates mediators. Since canonical wrappers do not perform any complex
translation, mediators have to deal with that. Apart of translation mediators
carry out broking tasks between domain-crossing components (e.g. combination
of Yellow Pages and geographical data [Yahoo]).
In our framework, a mediator can be seen as a processing entity which receives
a graph as input and produces a graph as output. Thus, a mediator dynamically
performs transformation of graph instances. Every such graph contains generically
represented protocol, language and data information.
Given the complexity of mediation, it is of advantage to build mediators automatically according to some machine-readable specification [GMPQ+97]. Further essential ability of mediators is to learn about wrapper interfaces. Having a message (graph instance) produced by the wrapper, the mediator can directly obtain the interface description (metadata) belonging to the message. In (Sec) we briefly mentioned that metadata (in RDF vocabulary, schema information) pertaining to an RDF model is itself represented as an RDF model. Thus, the metadata can embody generic representation of high-level mediator specification languages, ontology descriptions, schema mappings etc. Candidates for such languages could be logic-based language MSL [GMPQ+97], rule-based YATL [CDSS98] as well as declarative language BRIITY [HST99].
Summary In this section we discussed task separation and design principles of wrappers and mediators using generic representation. Canonical wrappers provide a standard interface to specific applications representing native component interfaces in a generic manner. Mediators perform transformations of graph instances exchanged between canonical wrappers, clients and other mediators. The mediation infrastructure we propose does not require common schemata and languages.
In this section we do not present a concrete proposal of how this basic transport function should be mapped to the existing variety of application-independent protocols like TCP/IP, CORBA/IIOP, HTTP etc. We believe, even such core protocol features as statefullness or synchronization do not have to be addressed at this level. They are intentionally omitted to reduce the overhead which would burden integration of applications that need only a limited set of communication primitives. We postpone the discussion of minimal protocol mappings until we have gathered more experience with prototype implementations. To illustrate the simplicity of such interface, a CORBA-oriented mapping would provide one or two standard method calls. In case of TCP/IP it would probably be enough to simply read from and write to a full-duplex connection.
The universal interface we suggest provides no built-in dispatch functionality like it is common in distributed computing. Instead, we propose an approach similar to the "generic dispatch" used in Garlic and the Dynamic Invocation Interface (DII) in CORBA. Rigid interfaces are not flexible enough to adequately address mixing and partial understanding crucial for the evolvability (Sec).
Generic dispatch can be used to organize component functions in a modular and extendable way. As explained in (Sec), by means of namespaces it is possible to divide application logic into modules implementing semantically coherent functions. A layered architecture can be built up of processing entities exchanging RDF models (Fig). In Digital Libraries, for example, a session management processing entity could maintain session information needed for the support of a stateful communication protocol. Thus, session management could be realized as an auxiliary module for the digital library core. Within a single address space RDF models can be passed by reference making parsing of serialized messages unnecessary.
Processing entities (PEs) can create, modify and exchange RDF models. Every PE supports a specific vocabulary, i.e. is capable of "understanding" a certain set of concepts identified by namespaces. Every namespace corresponds to an RDF schema in which meaning of concepts is defined in a machine-readable way. Thus PEs perceive a directed labeled graph containing a number of nodes and arcs carrying well-defined semantics. An RDF model may contain information not understood by a given PE. These parts of the graph can be considered invisible for this PE. In this manner, several PEs may work on a single RDF model.
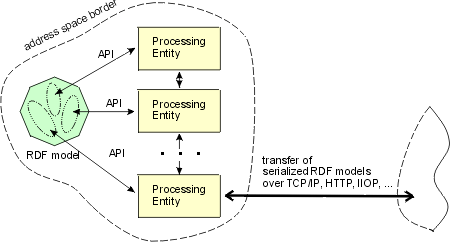
Using the layered architecture described above it is possible to develop efficient applications. Since parsing of the message is done only once within an address space, no special coding and decoding of the message parts by the modules is required (compare this approach with OSI layers where every layer appends its own header and control information). No central dispatcher is needed since every layer processes only parts of the graph it can understand. We believe, the layered architecture enables flexible design of extensible and maintainable components including wrappers, mediators and components natively using the interface we propose.
We propose a framework which we believe is generally suitable for facilitating interoperability between heterogeneous information systems and is not limited to quering. Instead of specifying common protocols, languages or data models we suggest an RDF-based representation in which protocols, languages and data are represented in a generic manner but still maintain their diversity and ontological specifity. In TSIMMIS, a similar idea was introduced with the Object Exchange Model (OEM) [PGMW95]. However, OEM was used only for data representation (no protocols and languages) and lacked machine-readable schema information. Abstracting out representational details of underlying data has been examined in [MIKS99].
TSIMMIS provides interface descriptions using declarative specifications of query capabilities of each data source. By contrast, wrappers in Garlic dynamically participate in query planning by implementing negotiation interface. We consider functions like query planning, transaction support, joins etc. application-specific. They may be exported by canonical wrappers if supported by native components. Otherwise, it is a task of mediators.
In our framework, wrappers provide declarative descriptions of their interfaces which reach beyond querying. In fact, all data pieces exchanged within the mediation infrastructure have metadata describing their semantics. However, we do not propose a particular language used for these interface descriptions. This aspect is further addressed in [HST99, GMPQ+97, CDSS98]. In InfoQuilt [SS98], metadata (schema) correlations are described using RDF.
Apart of a mediation infrastructure our framework provides an environment for implementing distributed applications. In some respects, it resembles distributed object middleware like RPC and CORBA. Due to evolvability inherent to RDF, major advantages can be achieved using the generic representation with respect to extensibility of applications and exchange of structured data. The layered architecture we describe resembles a refined application layer of the OSI Reference Model for computer networks. For message delivery we employ generic dispatch (single invocation point) similar to that used in Garlic.
As pointed out in [PCGM+98], mediation approaches are particularly strong in supporting the criteria of autonomy, ease of use, and scalability. Drawbacks lie mostly in the area of ease of contributing a new component, because whenever a new component is added, a corresponding wrapper needs to be built as well.
To address these drawbacks we propose canonical wrappers with explicit focus on simplicity and evolvability. Canonical wrappers can be built from scratch in a straight-forward way using concepts and structures of native components. They are not required to support any high-level languages, models or features not existing in the component. The representation standard we use (RDF) facilitates evolvability and allows to minimize the costs of infrastructure. Wrappers and mediators can be built using a layered architecture which contributes to efficiency and scalability of mediation.
Gaining more experience with the infrastructure we consider precise specification of protocol mappings. Further important step is integration of existing specification languages into the infrastructure to facilitate automatic mediation. We also plan to evaluate the application of the framework for Digital Library Interoperability.
| AKH96 | Yigal Arens, Craig A. Knoblock and Chun-Nan Hsu: Query Processing
in the SIMS Information Mediator. Advanced Planning Technology, Austin
Tate (Ed.), AAAI Press, Menlo Park, CA, 1996
http://www.isi.edu/sims/papers/96-arpi-book.ps |
| BBB+97 | R. Bayardo, W. Bohrer, R. Brice, A. Cichocki, G. Flowler, A.
Helal, V. Kashyap, T. Ksiezyk, G. Martin, M. Nodine, M. Rashid, M. Rusinkiewicz,
R. Shea, C. Unnikrishnan, A. Unruh, and D. Woelk: InfoSleuth: Semantic
Integration of Information in Open and Dynamic Environments. Proc.
ACM SIGMOD Conf., Tucson, Arizona, pp. 195-206, 1997
http://www.mcc.com/projects/infosleuth/publications/sigmod97.fm.html |
| BCV99 | S. Bergamaschi, S. Castano and M. Vincini: Semantic Integration
of Semistructured and Structured Data Sources. SIGMOD Record 28:1,
Mar 1999
http://www.acm.org/sigmod/record/issues/9903/special/berg.ps.gz |
| BL99 | Tim Berners-Lee et al. The Design Issues of the World Wide Web,
1999
http://www.w3.org/DesignIssues/ |
| CDSS98 | Sophie Cluet, Claude Delobel, Jérôme Siméon,
Katarzyna Smaga: Your Mediators Need Data Conversion! Proc.
ACM SIGMOD Int. Conf., pp. 177-188, 1998
ftp://ftp.inria.fr/INRIA/Projects/verso/VersoReport-138.ps.gz |
| GMPQ+97 | H. Garcia-Molina , Y. Papakonstantinou , D. Quass , A. Rajaraman
, Y. Sagiv , J. Ullman , V. Vassalos, J. Widom: The TSIMMIS approach
to mediation: Data models and Languages. Journal of Intelligent Information
Systems, 8:2, pp. 117-132,1997
ftp://www-db.stanford.edu/pub/papers/tsimmis.ps |
| HC98 | Mike Higgs, Bruce Cottman: Solving the Data Inter-operability
Problem using a Universal Data Access Broker. IEEE Data Engineering
Bulletin 21:3, pp. 34-42, Sep 1998
ftp://ftp.research.microsoft.com/pub/debull/sept98-a4final.ps |
| HST99 | Härder, T., Sauter, G., Thomas, J.: The Intrinsic Problems
of Structural Heterogeneity and an Approach to their Solution, in:
The VLDB Journal 8:1, 1999
http://wwwdbis.informatik.uni-kl.de:8080/publications/HST99.VLDB.html |
| KS97 | V. Kashyap and A. Sheth: Semantic Heterogeneity in Global
Information Systems: The Role of Metadata, Context and Ontologies.
In M. Papazoglou and G. Schlageter (Eds.), Boston: Kluwer Acad. Press,
1997
http://lsdis.cs.uga.edu/lib/download/KS97.ps |
| Le98 | Barry M. Leiner: The NCSTRL Approach to Open Architecture for the
Confederated Digital Library. D-Lib Magazine, Dec 1998
http://www.dlib.org/dlib/december98/leiner/12leiner.html |
| LP95 | Ling Liu and Calton Pu: Distributed Interoperable Object
Model and Its Application to Large-scale Interoperable Database Systems,
In Proc. of ACM International Conf. on Information and Knowledge Management
(CIKM'95), Baltimore, Maryland, USA, Nov 1995
http://web.cs.ualberta.ca/~lingliu/pictures/cikm95.ps |
| LSK95 | Alon Y. Levy, Divesh Srivastava and Thomas Kirk: Data Model
and Query Evaluation in Global Information Systems. Journal of Intelligent
Information Systems, 5:2, pp. 121-143, Sep 1995
http://www.research.att.com/~levy/jiis95.ps.Z |
| MIKS99 | E. Mena, A. Illarramendi, V. Kashyap, and A. Sheth: OBSERVER:
An Approach for Query Processing in Global Information Systems based on
Interoperation across Pre-existing Ontologies. Distributed and Parallel
Databases Journal, 1999
http://lsdis.cs.uga.edu/lib/download/MIKS-dapd98.ps |
| PBC+99 | A. Paepcke, M. Baldonado, C. Chang, S. Cousins, and H. Garcia-Molina:
Using Distributed Objects to Build the Stanford Digital Library Infobus.
IEEE Computer , Feb. 1999
http://computer.org/computer/co1999/r2toc.htm |
| PCGM+98 | A. Paepcke, C. K. Chang, H. Garcia-Molina, and T. Winograd: Interoperability
for Digital Libraries Worldwide. Communications of the ACM 41:4, pp.
33-43, 1998
http://www-db.stanford.edu/pub/papers/interop-cacm.ps |
| PGMW95 | Y. Papakostantinou, H. Garcia-Molina, and J. Widom: Object Exchange
Across Heterogeneous Information Sources. In Proc. of IEEE Int. Conf. on
Data Engineering (ICDE), Taipei, Taiwan, pp. 251-260 Mar. 1995
http://www-db.stanford.edu/pub/papers/icde95.ps |
| RDF99 | Ora Lassila, Ralph R. Swick (Eds.): Resource Description
Framework (RDF) Model and Syntax Specification. W3C Recommendation,
1999
http://www.w3.org/TR/REC-rdf-syntax/ |
| Re96 | Ron I. Resnick: Bringing Distributed Objects to the World Wide Web,
1996
http://www.interlog.com/~resnick/ron.html |
| RS97 | Mary Tork Roth, Peter M. Schwarz: Don't Scrap It, Wrap It! A Wrapper
Architecture for Legacy Data Sources. Proc. 23rd VLDB Conf., Athens,
Greece, pp. 266-275, 1997
http://www.almaden.ibm.com/cs/garlic/vldb97wrap.ps |
| SS98 | Kshitij Shah and Amit Sheth: Logical Information Modeling of
Web-accessible Heterogeneous Digital Assets. Proc. of the Forum on Research
and Technology Advances in Digital Libraries, (ADL'98), Santa Barbara,
CA. pp. 266-275, 1998
http://lsdis.cs.uga.edu/lib/download/SS98.ps |
| Wie92 | G. Wiederhold: Mediators in the Architecture of Future Information
Systems. IEEE Computer, 25:38-49, 1992
http://www-db.stanford.edu/pub/gio/gio-papers.html#AFIS |