|
The Simple Digital Library Interoperability Protocol (SDLIP) |
|
The Simple Digital Library Interoperability Protocol (SDLIP) |
Contents:
1.1 Grouping of Operations Into Interfaces
1.2 Different Ways of Using SDLIP
1.3 When Can Servers Discard State?
2.1 Search Interface
2.2 The Delivery Interface
2.3 The Result Access Interface
2.4 The Source Metadata Inferface
3.1 Property Lists
3.2 Exceptions
3.3 SearchResult
3.4 Subcollection Specifications
3.5 Source Metadata
4. Implementing SDLIP With HTTP/CGI
5. Interface Definition Language (IDL) Specification
Appendix A: Error codes and their meanings
This document describes the Simple Digital Library Interoperability Protocol (SDLIP; pronounced S-D-Lip). Clients
use SDLIP to request searches to be performed over information sources. The result documents are returned synchronously,
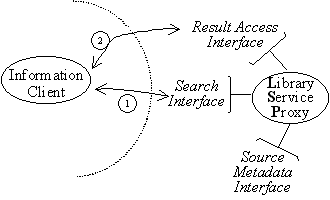
or they are streamed from service to client as they become available. Figure 1 shows a typical example of where
SDLIP is relevant.
|
|
The 'Library Service Proxy' (LSP) in Figure 1 wraps the external source. Through its back end, the LSP interacts with the external service via the transport and higher-level protocols required for that service. At the front end, the proxy supports SDLIP. Of course, an information source may itself provide SDLIP access. In that case, the client can interact directly with the source. One LSP may serve out multiple 'subcollections'.
The basic interaction is for the client to request a search across the network. Part of the request specifies how many documents are to be returned initially, once the search will be complete. The request also specifies which portion of each document is to be returned. For example, the client might ask for authors and titles of the first 10 documents to be returned right away. The client may later request more documents of the result, or it may request additional portions of the documents already delivered.
SDLIP has the following goals:
Figure 2 shows how the SDLIP operations are divided into four interfaces. One for the client, and three for the service (i.e. for the LSP).
|
|
The result access interface allows client applications to access the set of result documents, wherever that set is maintained. The source metadata interface, finally, allows clients or services such as metasearch engines to question a library service proxy about its capabilities. This might include a list of the subcollections served by the LSP, or the attributes that may be searched.
The partitioning into interfaces has three advantages. First, the interfaces make it clear which role each operation plays, and for which participants of the search transaction the operation needs to be implemented. Second, the interface notion enables clean expansions to the protocol in the future. One can subclass the existing interfaces to accommodate more elaborate facilities, or one can add additional interfaces. For example, one could use interface inheritance to add operations to the source metadata interface, if in the future some LSPs wish to export additional metadata, or wish to export that data in some new format. Or maybe one might want to add a whole new interface for financial transactions. Neither of these expansions would impact the existing core protocol. A third advantage of organizing SDLIP's operations into functionally coherent interfaces is that for some scenarios, or 'configurations', some of the interfaces are not needed. Rather than having to list various operations to be dropped for these cases, we can then simply say that interface X is not needed. For example, if clients always request information search results to be returned synchronously, then no delivery interface is needed.
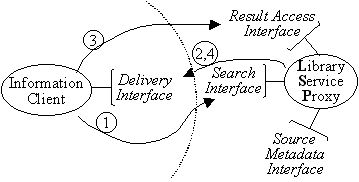
SDLIP can be used in many configurations. Figure 3 shows some examples. The simplest is the configuration of Figure 3a. It features one library service proxy serving the information, and a single client application object. The client submits the search request synchronously via the service's search interface (1). The results are returned as part of that call. Later, the client might, again synchronously, ask for more documents of the same result set (2).
|
Figure 3a: Synchronous requests for search, and follow-up information |
Figure 3b: Asynchronous operation. Client application implements delivery interface |
|
Figure 3c: Asynchronous operation. Separate cache in client application's address space implements delivery interface |
Figure 3d: Client asynchronously accesses asynchronously constructed cache in a third address space |
|
Figure 3e: Server delegates delivery (network boundaries are omitted for clarity) |
Figure 3: Different Configurations for Using SDLIP |
Therefore, Figure 3b adds asynchronous operation by including the delivery interface on the client. The client requests the search (1). The service uses the delivery interface to return the results one by one as they become available, or in batches (2). The client may ask for more documents, or additional portions of documents already submitted (3). The client's delivery interface is again used to move the information to the client (4). The drawback of this configuration is that every client application now needs to carry the responsibility of implementing the delivery interface.
To get around this problem, Figure 3c adds a 'result cache' object on the same machine as the client application
(as indicated by the dotted network partition arc). The client application creates this object, and then submits
the asynchronous search request to the service (1). As part of this request, the client informs the service of
where to find the object that implements the delivery interface. The client application can now continue to operate,
while the result cache object faithfully awaits arrival of the results. Once the results have arrived (2), the
client application uses the result access interface to pull them out of the result cache one by one (3). In Figure
3c, the result access interface is invoked synchronously. If the client should be able to ask its local result
cache for portions of the result that were not requested as part of the search, then the LSP in Figure 3c would
also need a result access interface. The cache would then forward requests for locally unavailable portions of
the result to the LSP.
Figure 3d is a variation of Figure 3c in that the result cache is created on a machine other than the one running the client application. This configuration is useful for thin clients interacting with services that do not maintain state at all, or only for short periods of time. In order to make due with little client-side memory, the result cache can receive results on the client's behalf, and can store them until the client extracts, uses, and discards one document (or even document portion) at a time. Apart from decreased memory requirements for the client, this configuration saves the day when the connection between client and service is frequently interrupted, as might be the case with mobile clients connected through wireless networks. In such a scenario, the mobile client might be out of touch for several days. In the configuration of Figure 3c, the service might make some failed connection attempts to deliver results. It would then eventually discard the session state, leaving the client disappointed, once it is finally back on the network. If the result cache is placed at a stationary point that is well connected with the service, the results are safe and accessible once the client returns to the network.
Figure 3e, finally, illustrates how services can delegate interactions with clients if the service object gets overloaded (2), yet wishes to maintain state for the client. As part of the delivery interface, servers can specify a future contact address (3). All future deliveries are made by the delegate. If the client wishes, for example, to recall more documents of the result set than it asked for in its initial search request, then it will use the delegate's address, rather than the main address (4).
If SDLIP claims that it enables both stateful and stateless implementations of servers, how do clients and servers agree on whether or not there is state at the server? The notion of a 'state parking meter' takes care of this. It is a very simple notion.
When clients submit a search request to a server, they include the amount of time they would like the service to retain the state associated with the session. The server returns the actual time it is willing to maintain the result set and related state. For a completely stateless server, this time could be zero. The clock starts ticking right after the search call returns. Once the time has expired, the server is free to discard all state associated with the search. The client, meanwhile, has the option of invoke an 'extend state timeout' operation on the server to add additional time. The server has the option of granting or refusing the request. This is rather like the client feeding a parking meter. Note that this scheme ignores some uncertainties in that the server and client clocks might not be synchronized. Also, the server starts its clock when it returns from the search call, while the client starts counting down when the return process is complete. Since state maintenance times are expected to be large compared to these differences, the issue is ignored in favor of simplicity.
Let's get to specifics. Section 2 will describe SDLIP operations in detail. Section 3 explains the XML structures used with SDLIP. Section 4 explains how simple HTTP/CGI transactions can be used to implement SDLIP. Section 5, finally, summarizes SDLIP's specification, using CORBA's interface definition language (IDL). This section can be used as a summary of the material in Section 2. The Appendix A, finally, lists the error codes used in SDLIP.
We describe each interface in turn. For each interface, we list the associated operations, and explanations for each parameter. Whenever a parameter is a specially encoded XML string, we just state its purpose. Section 3 defines the XML formats in more detail. For clarity, we do summarize the simple XML property list format ahead of time below.
Some technologies that might be used to implement SDLIP allow parameter defaulting. For example, an implementation based on HTTP benefits from sending as few parameters as possible for each operation, since parameters must all be encoded in the URL. For such implementations, we specify defaults for as many parameters as possible in the operations defined below. Whenever a parameter can be left out, its default value is specified in curly braces in the parameter explanations.
Note that the interfaces described here can be used directly to describe CORBA implementations of SDLIP. That
is, CORBA objects that implement these interfaces are proper implementations of SDLIP. In fact, the CORBA IDL description
of the interfaces in Section 5 is the basis for the descriptions
of SDLIP operations in this section. Remember, however, that all the operations described here can also readily
be implemented using HTTP/CGI instead. See Section 4 for details
on how to do this, and for an implementation example.
First, a couple of conventions we follow, and some very brief preview implementation hints to set the reader at ease about how these operations might work in a real system.
Entity Addresses: When we use the word 'address' to specify the target of a method invocation, we could use the term 'object identifier' (OID). We instead use the term 'address', so that the mapping to HTTP/CGI based implementations is more obvious. The realization of 'address' in that case is, of course, a URL.
Property Lists: Some of the method parameters below are property lists. These are XML-encoded lists of attribute value pairs. For example:
<propList> <prop key="Quality of service">Fastest</prop> <prop key="UserID">Miller</prop> </propList>
We use property lists as a catch-all expansion facility. Since property lists can be as large as needed, they are a great way to take care of special needs that arise in the future, and cannot be included in a core protocol, such as SDLIP. For the formal DTD of property lists, see Section 3.1.
We introduce the following convenience type for clarity when a parameter is supposed to be an XML-encoded propery list:
typedef PropList String; // XML-encoded list of property value pairs.
Returning values: All information that operations return to callers are passed back in OUT parameters.
Consequently, the return type of all operations is Void. For distributed object implementations, OUT parameters
are a familiar notion. The SDLIP HTTP/CGI binding specifies how one or more OUT parameters are returned for GET
and POST calls.
Error reporting: Operations may raise errors instead of returning normally. The information returned is always an XML-encoded string as defined in Section 3.2. It includes information about the type of exception, a short description, and possibly additional debug information. For distributed object implementations, exception delivery can be realized as regular exception events within the programming language being used. For HTTP/CGI implementations, the HTTP status return is used, as explained in Section 4.
The searchAsynch() method allows clients to transmit a query to a target library service proxy (LSP).
Void searchAsynch( // Submit query. Result to be delivered by
// calls to the deliveryTarget.
Long clientSID, // {0} Client-side session ID (unique within client)
String subcols, // {service's default (or sole) subcollection}
// Collections or previous results to search w/in LSP
String queryLang, // {service's (well-known) default language}
// Query language used for the query
String query, // The query
Long numDocs, // {10}Number of documents to return (-1: all)
String[] docProps, // {all possible properties} Properties to return for
// each result doc (e.g. ['Abstract', 'Title', ...])
Long stateTimeoutReq, // {3600 (i.e. 1hr)}Request for number of seconds to
// maintain state at server. -1: request unlimited time
PropList queryOptions, // {null} Additional info for the LSP
Delivery retTarget // Address of the entity that implements a delivery interface
)
The client invents a session ID, which allows the service proxy to refer to this query request later on. This ID only needs to be as unique as the client requires. LSP implementations use their own internal mechanisms to separate sessions with different clients.
The subcols parameter is used when one LSP serves out many collections. This is sometimes true for commercial information providers, or for Z39.50 sites. If an LSP only serves one source of information, this list can be empty. A special case of subcollection are the result sets of previous searches: For the purpose of query refinement, clients must be able to specify such existing result sets within the LSP. The subcollection string is formated like this (for details on 'server sessionIDs, see later in this document):
<subcols> <subcol>[subcollection name]</subcol> <resSet>[server sessionID]<resSet> <resSet>[server sessionID]<resSet> <subcol>[subcollection name]</subcol> <resSet>[server sessionID]<resSet> </subcols>
One or more result sets or subcollections may be specified in any order. See Section 3.4 for details on the format of this string.
The query language parameter specifies which query language is being used. SDLIP does not specify a vocabulary for this parameter. The query parameter is a string that contains the query.
The numDocs parameter specifies how many documents the LSP is to return initially. A value of '-1' means 'return all documents that are found'. Remember that the client may use the result access interface later on to request additional documents.
The docProps parameter is an array of strings. These are the names of document properties the LSP is to return for each of the result documents. One example value is ['Title', 'Author']. A more involved example is ['USMARC.245', 'DublinCore.Creator']. The detailed format of the property names is not part of the SDLIP standard. But SDLIP does assume that a dot notation may be used to introduce the 'attribute model' within which the name of the respective attribute should be interpreted. For example, USMARC.245 is assumed to denote 'author' in the Library of Congress' USMARC attribute model. When no dot is present, a 'default' attribute model is assumed by the LSP. (See related information on these metadata issues).
The stateTimeoutReq is the number of seconds the client would like the server to hold on to the result set. After that time, the server may discard the result state. A value of -1 requests that the server hold state indefinitely, or until the client calls cancelRequest(). The setSessionInfo() method of the delivery interface allows the server to inform the client of the number of seconds the server is actually willing to hold the state.
The queryOptions parameter is a property list that is not further defined by SDLIP. Clients and services may use properties to hold additional information regarding the query being transmitted. For example, the property list might be used to pass authorization information, financial arrangements, or quality of service specifications to the LSP.
The retTarget, finally, is the address to which the LSP is to deliver results. For a distributed object implementation this would be an object that implements the delivery interface.
The searchSynch() method is the synchronous cousin of searchAsynch().
Void searchSynch(
Long clientSID, // {0} Client-side session ID (unique within client)
String subcols, // {service's default (or sole) subcollection}
// Choice of collections to search w/in LSP
String queryLang, // {service's (well-known) default language}
// Query language used for the query
String query, // The query
Long numDocs, // {10} Number of documents to return (-1: all)
String[] docProps, // {all possible properties} Properties to return
// for each result doc (e.g. ['Abstract', 'Title', ...])
Long stateTimeoutReq, // {3600 (i.e. 1hr)} Request for number of seconds to
// maintain state at server. -1: request unlimited time
PropList queryOptions, // {null} Additional info for the LSP
OUT Long stateTimeout, // {0} Time server is willing to maintain state
OUT Long serverSID, // {0} ID by which server identifies this session
OUT ResultAccess serverDelegate, // {same as for original query} For followup requests
OUT SearchResult result // XML-Encoded result list.
)
In contrast to searchAsynch(), searchSynch() blocks until the LSP has finished setting up the result set. Then the result is returned in the OUT parameter. Arguments are identical to searchAsynch() (see above), except that no callback address is needed, and the result is returned as an OUT parameter. This return type is an XML string that contains a list of numDocs documents (if that many were indeed found). For each document, only the attributes specified in docProps are returned. The format of the SearchResult type is explained in Section 3.3. The searchSynch() does have three additional parameters: stateTimeout, serverSID, and serverDelegate. The first is the number of seconds the server is willing to to hold the state. The second is the session ID the server uses to identify this session. All correspondence with the server regarding this session must include that ID. Using a separate session identifyer for the client and the server avoids having to invent globally unique IDs. The serverDelegate parameter, finally, is the address the client should use if it wants to retrieve additional information from the result set.
If the client has submitted a searchAsynch() request, and wishes to abort the search:
Void cancelRequest(
Long serverSID, // {0}
)
The reqID refers to the particular request within the session that is to be canceled. This is a client-side ID used for follow-up requests issued after an initial search request (see getDocsAsynch()). Use 0 to cancel the original search and all pending follow-up requests. This will be discussed further.
The delivery interface allows library service proxies to deliver documents to the client asynchronously. The scenario is that the client has issued a searchAsynch() request to the LSP at some earlier time. The LSP has been processing the request. Now at least some of the results are available. The LSP uses the delivery interface to return the requested documents (or document pieces) to the client. They are either delivered all in one bunch, or piece by piece as the LSP can pull the information out of the underlying information repository.
The setSessionInfo() call lets the client know how many results are (at least expected to be) available at the LSP. Note: this is not the number of documents already delivered to the client. It is the size of the result set.
Void setSessionInfo( // Expected total number of deliverable docs
// in response to a searchAsynch().
Long clientSID, // {0}
Long serverSID, // {0} ID used at server to identify this session
Long ResultAccess serverDelegate, // {same as for original query}
// Server-side delegate to use for this session.
Long expectedTotal, // {0} If -1: number is unknown.
Long stateTimeout // {0}
)
The serverSID is the session ID the server uses to identify this session. All correspondence with the
server regarding this session must include that ID. The serverDelegate is the same as the parameter of
the same name in searchSynch(): an address for the client to use for follow-up information regarding this
session. If NULL, there is no change in address.
Sometimes, the total number of results cannot be determined by the LSP. For example, if an LSP continuously
serves out a stream of documents matching a 'standing' query, and the underlying source is constantly being added
to, then setting the total number of documents does not make sense.
The stateTimeout parameter is the number of seconds the server is willing to maintain state.
The addDocs() method is the most important operation of the delivery interface. It transfers the documents from the service to the client.
Void addDocs( // Add results to a client-side Delivery entity
Long clientSID, // {0} The client-side session ID
Long reqID, // {0} 0 if this call was triggered by the
// original call to searchAsynch(). Else see
// getDocsAsynch() for an explanation of
// this parameter
SearchResult result // XML list of results
)
The clientSID is the same that was passed in the original searchAsynch() call. It helps the client keep track of why these results are being delivered. There is also a reqID. This is zero if the results are the reponse to an initial searchAsynch(). If they are the result of a previous getDocsAsynch() call, then the request ID provided by the client as part of that call will be returned in this parameter.
The result parameter, finally, is the meat: it is the XML-encoded list of result documents. See Section 3.3 for details on how this string is structured.
The raiseException() method on the delivery interface is used when something went wrong with an asynchronous search or document retrieval request.
Void raiseException(
Long clientSID, // {0}
Long reqID, // {0}
ExceptionReason errDesc // XML-Encoded information on the reasons for the failure
)
The ExceptionReason is an XML-encoded list of reasons for the failure, which includes for each exception: an exception type, a short description of the failure, and a property list of additional information, such as stack traces. See Section 3.2 for details on the format of this XML string. Note that if the delivery interface is implemented by a result cache (as in Figure 3d), then the exception will make it back to the client only when the client attempts the next result access through the result access interface.
Once some of the documents have been returned, clients might want to get more documents than they had originally requested, or they might need to request additional properties of documents they already have. This is accomplished through the result access interface.
The getSessionInfo()allows clients to find out about the result set:
Void getSessionInfo()
Long serverSID, // {0}
OUT Long expectedTotal,// {0} -1 if unknowable. -2 if not yet known.
OUT Long stateTimeout // {0} Total number of seconds server is willing to
// hold state. -1 if forever.
)
The expectedTotal return parameter is -1 if the remote LSP has indicated that the total number of documents
cannot be determined. If the callee simply does not know yet, but there is a chance that it will find out later,
a -2 is returned.
The stateTimeout is the total number of seconds that the server is willing to hold the state without
receiving an extendStateTimeout() call.
The getDocsAsynch() operation, and its synchronous cousin getDocsSynch()are the means by which clients ask for more documents, or for additional portions of partially transfered documents in a result set. The key notion is that client and server think of the result documents as being arranged in order within a result array. Documents are referenced by their zero-based index into that array.
Void getDocsAsynch( // Used to get more docs in existing session
Long serverSID, // {0} ... of the original query
Long reqID, // {0} new for each call
String[] docProps, // {all possible properties} properties to get
String docsToGet, // {-1} Doc indexes to get. Ex: "1,2,5-11". "-1" :all
Delivery retTarget
)
The serverSID is the session number that was established during the original search request. The reqID is an identifyer for this particular request within the overall session. It is used when results are being delivered to distinguish between multiple, simultaneous outstanding getDocsAsynch() requests. The reqID can also be used to cancel this particular delivery request (see cancelRequest()).
The docProps is the same kind of parameter that is used in the searchAsynch() call: it specifies which document properties should be included with each document.
The docsToGet parameter specifies which documents to get. This is a comma-separated list of integers. The only non-numeric character allowed is "-". A "-" character between two numbers is a range indicator. For example, "1,3,5-7" will retrieve documents 1, 3, 5, 6, and 7. A "-1" at the beginning of the string, or after a comma refers to all documents from beginning to end, or from the previous index, respectively. For example: "-1" requests all documents. "1,3,-1" requests documents 1, 3, 4,... all the way to the end.
getDocsSynch() is the synchronous version of getDocsAsynch(). Parameters are as described there. The return parameter is described in Section 3.3.
Void getDocsSynch( // Returns a SearchResult XML string
Long serverSID, // {0} ... of the original query
Long reqID, // {0} new each time
String[] docProps, // {all possible properties} properties to get
String docsToGet, // {-1} document indexes to retrieve. -1 for all.
OUT SearchResult result
)
When the originally agreed upon time limit for result state maintenance is about to expire, the client needs
to call
extendStateTimeout(), if the client still wishes to access that state.
Void extendStateTimeout(// Request more time for server to
Long serverSID, // {0} maintain search result state.
Long additionalTime,
OUT Long timeAllotted // Num of secs server agrees to maintain state
)
The LSP returns the amount of additional time it is actually willing to maintain the state for the client.
Alternatively, sometimes, a client may want to release server state prematurely, or it may have changed its mind about a request it delivered earlier. It can use cancelRequest() for these situations:
Void cancelRequest(
Long serverSID, // {0}
Long reqID // {0}
)
The reqID is 0 if all outstanding requests for this session are to be canceled. This has the semantics of closing the session, and allowing the server to free its resources. If reqID is not zero, only the corresponding request within the session is canceled.
Sometimes, you may want to clean out the result cache:
Void removeDocs( // Remove specified docs from the result
Long serverSID, // {0}
String docsToRemove // {-1} If -1, remove all documents.
)
The docsToRemove parameter contains a specification of the documents to remove. This is a comma-separated list of integers. The only non-numeric character allowed is "-". See Section 2.1 (call to getDocsAsynch()) for details on the format of this. The recipient of the removeDocs() call is allowed to refuse the deletion. In that case an eUnauthorized exception is raised.
The interface for asking sources about their capabilities is as follows.
Void getVersion( // Get info about LSP's interfaces
String interfaceName, // {Search} Search, Delivery, ResultAccess, Metadata
OUT VersionInfo version // XML-encoded info about the version
)
The interface name must be one of Search, Delivery, ResultAccess, or Metadata. The returned value contains information about the respective interface. See Section 3.5 for details on the information that is returned.
Void getSubcollectionNames( String subcols // XML list of subcollections served by LSP )
Void getPropertyInfo( // Returns attrList XML string
String subcolName, // {null} If not supplied, request for default subcollection.
OUT AttrList propInfo // Acceptable attributes for the
// subcollection, and whether they are
// searchable/retrievable
)
This method allows clients to retrieve information about which document properties may be searched or retrieved for the specified subcollection. The format of the AttrList information about supported document properties is covered in Section 3.5.
In order to keep SDLIP's datatypes simple, parameters that contain multiple pieces of information are encoded as XML. this section describes these XML formats. XML has some primitive data types that are difficult to remember. Here are the ones to choose from. We use only ANY in the protocol. But remember that servers may create DTDs for the documents they return. So you might want to be aware of the differences. As best as I can tell, this is story:
An example of a property list is this:
<propList> <prop key="Quality of service">Fastest</prop> <prop key="UserID">Miller</prop> <propList>
Think of this as a dictionary, or list of key/value pairs. More formally, the DTD for XML-encoded property lists is as follows:
<!ELEMENT propList (prop*)> <!ELEMENT prop (#PCDATA)> <!ATTLIST prop key ANY #REQUIRED>
Exceptions are delivered in whatever form the underlying transport allows. In CORBA, exceptions are passed to
the recipient host over the network. Once at the destination host, the exception facilities native to the application's
programming language are used to deliver the exception to the recipient program. See the SDLIP CORBA specification
in Section 5 for details on the shape of exceptions for the SDLIP
CORBA binding. With the HTTP binding, every operation invocation returns one line of status, consisting of an error
code and a short, human-readable message. The status is then followed by an arbitrary amount of information.
No matter how exceptions are transported and delivered, SDLIP's core error information is a single XML-encoded string. This string can include information about multiple exceptions that might have occurred. For each exception, either two or three pieces of information are provided in this string: an error code, a human-readable message, and optionally a property list with additional information.
Here is an example. It signals two exceptions. The first is that the document index specified is out of range. The second is that even if the index were within range, you'd get no data because you haven't deposited enough money with the service:
<errs> <err> <code>404</code> <desc>Use of document index larger than result set</desc> <propList> <prop key="Debuglevel">4</prop> <prop key="Stacktrace">...</prop> </propList> </err> <err> <code>402</code> <desc>Your debit card has insufficient funds</desc> </err> </errs>
Note that the propList is optional (but you can have at most one).
The error codes follow a subset of HTTP conventions. All error codes are three-digit numbers. In SDLIP there
are two classes of error codes. Codes of the form 4xx indicate errors in the information supplied by the
client. Errors of the form 5xx indicate errors the server encountered, even though the client has supplied
correct information. See Appendix A for the full sets of codes.
Here is the DTD that goes with exceptions:
<!ELEMENT errs(err*)> <!ELEMENT err(code, desc, propList?)>
This kind of XML string is used to return result documents in response to a search. Optionally, the document's DTD is prepended. Here is an example. An explanation follows:
<!DOCTYPE SearchResult SYSTEM "http://www-diglib.stanford.edu/~testbed/SearchResult.dtd" [ <!ELEMENT props (author*, title, abstract)> <!ELEMENT author ANY> <!ELEMENT title ANY> <!ELEMENT abstract ANY> ]> <SearchResult> <doc> <DID>1</DID> <DT>text/ascii</DT> <props> <!-- result doc's properties are coded as per DTD above --> <author>Bill Smith</author> <author>Frank Miller</author> <title>This is My Life</title> <abstract>It's been great so far.</abstract> </props> </doc> <doc> ... </doc> </SearchResult>
For each document in a search result we communicate three pieces of information: its document ID (DID) which is a numeric index into the result set (zero-based), optionally some indication of the document type (DT), and the document's properties as requested by the client (i.e. author, title, etc). Note that exactly which properties are delivered depends on what the client asked for in its request (e.g. in the property list parameter of the searchAsych() call). How do we make the format of the SearchResult string flexible enough to accommodate this variation, yet maintain some predictability?
The special trick we use to accomplish this is to (optionally) include the XML string's DTD before the actual information. Of course, we don't want to repeat each time the fact that there will be a document ID, and maybe a document type. That will always be true, and we don't want to waste space on this info for every result we return. Instead, we just pass a pointer to a main, common part of the DTD (the 'SYSTEM' piece above). But then we add a piece of DTD that's special for the results returned in the subsequent body of XML. That's the set of '!ELEMENT' declarations above. This piece of DTD is generated by the server, and the client can either use it, or it can ignore this piece of structural information, and plunge ahead to the actual list of documents, parsing on its own, or simply passing the information to someone else.
Here is that 'universally known' piece of DTD, called SearchResult.dtd. It resides at the specified URL. The XML jargon for this is 'External DTD':
<!ELEMENT res (doc*)> <!ELEMENT doc (DID, DT?, props)> <!ELEMENT DID (#PCDATA)> <!ELEMENT DT (#PCDATA)>
Note that the 'props' element is not defined in this global portion of the DTD. It is defined in the subsequent DTD addition (i.e. the !ELEMENT declarations that precede the bulk of the information).
Notice that a server could generate a more elaborate structure for the documents. For example, the author field could be subdivided into first name initials and last name portions, and a 'pict' attribute could be added, which points to a gif image of the author:
<!DOCTYPE res SYSTEM "http://www-diglib.stanford.edu/~testbed/SearchResult.dtd" [ <!ELEMENT props (author*, title, abstract)> <!ELEMENT author initials, lastName)> <!ELEMENT initials (#PCDATA)> <!ELEMENT lastName (#PCDATA)> <!ATTLIST author pict ENTITY #IMPLIED> <!ENTITY Miller-pic SYSTEM "../Miller.gif" NDATA gif> <!ELEMENT title ANY> <!ELEMENT abstract ANY> ]>
<SearchResult> <doc> <DID>1</DID> <props> <author pict=&Miller-pic;> <initials>A.</initials> <lastName>Miller</lastName> </author> <title>How I Did It</title> <abstract>With lots of effort.</abstract> </props> </doc> <doc> ... </doc> </SearchResult>
When requesting a search, clients specify a set of subcollections and/or result sets to run the search over. This set is expressed as an XML string. For example:
<subcols> <subcol>New York Times</subcol> <resSet>3<resSet> <resSet>5<resSet> <subcol>Washington Post</subcol> </subcols>
This instructs the LSP to search over the New York Times, the Washington Post, and result sets produced in session
IDs 3 and 5.
The DTD for this is:
<!ELEMENT subcols (subcol | resultset)*> <!ELEMENT subcol (#PCDATA)> <!ELEMENT resultset (#PCDATA)>
When clients ask for a list of subcollections served out by the LSP (using the getSubcollectionNames(
) method in the Source Metadata interface), the server returns
an XML string that is similar to the one described above. The only difference in that case is the absence of any
result sets. The DTD for such strings is :
<!ELEMENT subcols subcol*>
<!ELEMENT subcol (#PCDATA)>
When clients ask LSPs for information about the properties that are available for the documents in the collections the LSPs serve out, an attribute list is returned. For example:
<attrList> <attr> <MID>10</MID> <!-- Model ID-> <AID>2</AID> <!-- Attribute ID-> <propList> <prop key="name">Length</prop> <prop key="searchable">0</prop> <prop key="retrievable">1</prop> </propList> </attr> <attr> <MID>10</MID> <AID>3</AID> <propList> <prop key="name">Price</prop> <prop key="searchable">1</prop> <prop key="retrievable">1</prop> <prop key="accessPermission">ALL</prop> </propList> </attr> </attrList>
Here is the corresponding DTD:
<!ELEMENT attrList (attr*)> <!ELEMENT attr (MID, AID, propList?)> <!ELEMENT MID (#PCDATA)> <!ELEMENT AID (#PCDATA)>
Implementations of SDLIP via HTTP use the commands GET and POST. All operations that are not part of the delivery interface submit an HTTP GET command to the service, encoding the parameters in the URI. In response to GET commands that return OUT parameters, servers always return a single XML document. The document either contains an error message (as defined above), or the collection of OUT parameters.
All operations of the deliver interface use the HTTP POST command. The URI of the POST command is the address
of the target. As with GET results, the body of the POST command is always an XML document containing the parameters
of the operation.
Parameter names used in the URIs of HTTP commands, or as tags for XML tags (see below), are the same names that
are used for those parameters in the definitions of the SDLIP operations.
Here is an example for the searchSynch() operation. In order to be readable, the URI is broken up into multiple lines, which would not be the case in a real GET command:
GET /searchSynch?clientSID=3& subcols=<subcols><subcol>Products</subcol></subcols>& queryLang=Keywords& query=color+printer& numDocs=1& docProps=title& stateTimeoutReq=-1& queryOptions=<propList><prop+key%3d"username">TestUser</prop> <prop+key%3d"password">Shhhhh</prop></proplist> HTTP/1.0
Notice that you may need to escape some HTTP-reserved characters. For example, the '%3d' above is the hex replacement for the '=' sign, which is illegal within a URI. Similarly with spaces, which must be replaced by '+' or by '%20'. Whenever a sequence of string is called for, encode the whole sequence like this:
Examples: ",author,title,abstract", or "|author|title", or just "|author".
The response to this request would be something like the following (remember that the DTD, the part starting with '<!DOCTYPE' and ending with ']>' is optional):
HTTP/1.0 200 0K CONTENT-TYPE: text/plain <parms> <parm nm="stateTimeout">3600</parm> <parm nm="serverSID">13</parm> <parm nm="serverDelegate"> <parm nm="serverDelegate">http://www-diglib.stanford.edu/cgi-bin/paepcke/sdlip/</parm> <parm nm="result"> <!DOCTYPE SearchResult SYSTEM "http://www-diglib.stanford.edu/~testbed/SearchResult.dtd"[ <!ELEMENT props (title)> <!ELEMENT parms ANY> ]> <SearchResult> <doc> <DT>text/plain</DT> <props> <title>The ACME Printer Prints Perfectly</title> </props> </doc> </SearchResult> </parm> </parms>
If an error occurred while processing the searchSynch() request, the status line of the return message
would contain the error code and a short message. The body of the return message would contain the SDLIP XML-encoded
error information. See Section 3.2 and Appendix
A for details on exception information.
Here is an example of how the POST command is used. This example implements the addDocs() method:
POST /addDocs HTTP/1.0 CONTENT_TYPE: text/plain
<parms> <parm nm="clientSID">3</parm> <parm nm="reqID">2</parm> <parm nm="serverDelegate">http://www-diglib.stanford.edu/cgi-bin/paepcke/sdlip/</parm> <parm nm="result"> <SearchResult> <doc> <DT>text/plain</DT> <props> <title>The ACME Printer Prints Perfectly</title> </props> </doc> </SearchResult> </parm> </parms>
Here, then is the list of SDLIP operations, and the HTTP command to use with each one:
Search interface:
Delivery interface:
Result access interface:
Source metadata interface:
Here is a copy of the CORBA IDL specification for the SDLIP interfaces.
///////////////////////////////////////////////////////////////////
//
// Simple Digital Library Interoperability Protocol (SDLIP)
//
// Documentation:
// Protocol is described at
// http://www-db.stanford.edu/~paepcke/shared-documents/sdlip/sdlip9.htm
// There are four interfaces in this module:
// - Search: methods used by clients to send queries to library
// services proxies (LSPs)
// - Delivery: methods used by LSPs to send results to clients
// - Result Access: methods used by clients to access query results
// - Metadata: methods used by clients to find out metadata info
// about the LSP and its collections
//
// Last Modified: Jan 7, 1999 (Arturo Crespo)
//
///////////////////////////////////////////////////////////////////
//
// Revisions:
//
// Tue Dec 29 14:20:37 1997 (Andreas Paepcke) paepcke@Haddock.Stanford.EDU
// Updated parameter names to be shorter.
// Wed Dec 16 11:11:37 1997 (Andreas Paepcke) paepcke@Haddock.Stanford.EDU
// Added server side session IDs. Modified calls to use them.
// Wed Dec 16 11:11:37 1997 (Andreas Paepcke) paepcke@Haddock.Stanford.EDU
// Allowed server delegation only as part of the searchSynch() and
// setSessionInfo() calls. Delegation no longer allowed in addDocs()
// Wed Dec 16 11:11:37 1997 (Andreas Paepcke) paepcke@Haddock.Stanford.EDU
// Added Subcollections typedef and changed subcols parms to that (used
// to be sequence of string in some cases.
module SDLIP {
// Forward references
interface Delivery;
interface ResultAccess;
// Basic definitions
typedef sequence <string> SeqOfString;
// XML Strings returned by
typedef string PropList;
typedef string SearchResult;
typedef string Subcollections;
typedef string ExceptionReason;
typedef string AttrList;
typedef string VersionInfo;
// Exceptions
exception SDLIPException {
string exceptionCode;
string exceptionReason;
};
///////////////////////////////////////////////////////////////////
// Search Interface
//
// The methods in this interface allow clients to send queries to a
// library server proxy.
//
///////////////////////////////////////////////////////////////////
interface Search {
// The searchAsynch() method allows clients to transmit a query to a
// target library service proxy (LSP). Result to be delivered by
// calls to the retTarget.
void searchAsynch(
in long clientSID, // Client-side session ID
in Subcollections subcols, // Collections or
// prev. results to search w/in LSP
in string queryLang, // Query language used for the query
in string query, // The query
in long numDocs, // Number of documents to return
// (-1: all)
in SeqOfString docProps, // Properties requested
in long stateTimeoutReq, // Number of seconds to maintain
// state at server (-1: unlimited)
in PropList queryOptions, // Additional info for the LSP
in Delivery retTarget // Address of the entity that
// implements a delivery interface
) raises(SDLIPException);
// The searchSynch() method is the synchronous cousin of searchAsynch().
void searchSynch(
in long clientSID, // Client-side session ID
in Subcollections subcols, // Choice of collections to search
in string queryLang, // Query language used for the query
in string query, // The query
in long numDocs, // Number of docs to return (-1: all)
in SeqOfString docProps, // Properties to return for each doc
in long stateTimeoutReq, // Number of seconds to maintain
// state at server (-1: unlimited)
in PropList queryOptions, // Additional info for the LSP
out long stateTimeout, // state timeout set at the server
out long serverSID, // Server-side session ID
out ResultAccess serverDelegate,// Address for future service requests
out SearchResult result // XML-Encoded result list.
) raises(SDLIPException);
// The cancelRequest() Method allows the client to cancel a session
// and/or request.
void cancelRequest(
in long serverSID, // session to be cancelled
in long reqID // request to be cancelled (0: cancel
// all requests of the given session
) raises(SDLIPException);
};
///////////////////////////////////////////////////////////////////
// Delivery Interface
//
// The methods in this interface allow library service proxies to
// deliver documents to the client.
//
///////////////////////////////////////////////////////////////////
interface Delivery {
// Add results to a client-side Delivery Object
void addDocs(
in long clientSID, // The client-side session ID
in long reqID, // reqID specified in
// getDocsAsynch() or
// 0 if this call was triggered by the
// original call to searchAsynch()
in SearchResult res // XML list of results
) raises(SDLIPException);
// The setSessionInfo method informs the client of session results
// on the server:
void setSessionInfo(
in long clientSID, // The client-side session ID
in long serverSID, // The server-side session ID
in ResultAccess serverDelegate, // Address for future service requests
in long expectedTotal, // Number of documents in result
in long stateTimeout // Time before servers dispose
// the session state (**** TOTAL)
) raises(SDLIPException);
// The raiseException() method is used to return errors encountered
// when something went wrong with a sarchAsynch() or
// with a getDocsAsynch() call
void raiseException(
in long clientSID, // The client-side session ID
in long reqID, // Request producing the error
in ExceptionReason errDesc // XML-Encoded information
// on the reasons for the failure
) raises(SDLIPException);
} ;
///////////////////////////////////////////////////////////////////
// ResultAccess Interface
//
// The methods in this interface allow clients to retrieve
// document results
//
///////////////////////////////////////////////////////////////////
interface ResultAccess {
// The getSessionInfo method returns information about an active session
void getSessionInfo(
in long serverSID, // The server-side session ID
out long expectedTotal, // Number of documents in result
out long stateTimeout // Time before server disposes
// the session state (**** TOTAL)
) raises(SDLIPException);
// The getDocsAsync method is Used to get more docs in existing session
void getDocsAsynch(
in long serverSID, // The server-side session ID
// of the original query
in long reqID, // new for each call
in SeqOfString docProps, // properties to get
in string docsToGet, // Doc indices to get
in Delivery retTarget // Address where results will be sent
) raises(SDLIPException);
// The getDocsSynch is the synchronous counterpart of getDocsAsynch()
void getDocsSynch(
in long serverSID, // The server-side session ID
// of the original query
in long reqID, // new each time
in SeqOfString docProps, // properties to get
in string docsToGet, // document indices to retrieve
out SearchResult res // SearchResult XML string
) raises(SDLIPException);
// The method extendStateTimeout() is used by the client to extend the
// time that result state is kept at the server
void extendStateTimeout(
in long serverSID, // the server-side session ID
in long additionalTime, // additionalTime (in seconds)
out long timeAllotted // time allotted by server (in seconds)
) raises(SDLIPException);
// The cancelRequest() Method allows the client to cancel a session
// and/or request.
void cancelRequest(
in long serverSID, // session to be cancelled
in long reqID // request to be cancelled (0: cancel
// all requests of the given session
) raises(SDLIPException);
// Remove specified docs from the result
void removeDocs(
in long serverSID, // server-side session ID
in string docsToRemove // ... from the result collection
) raises(SDLIPException);
};
///////////////////////////////////////////////////////////////////
// Metadata Interface
//
// The methods in this interface allow clients to ask servers about
// their capabilities
//
///////////////////////////////////////////////////////////////////
interface Metadata {
// Lists the version information of an interface served by a LSP
void getVersion(
in string interfaceName, // name of interface
out VersionInfo version // XML string with version info
) raises(SDLIPException);
// Lists all subollections served by the LSP
void getSubcollectioNames(
out SeqOfString subcols // subcollections served
) raises(SDLIPException);
// Returns property info of a specific collection
void getPropertyInfo(
in string subcolName, // If empty string, request for default
// subcollection
out AttrList propInfo // XML string with propertyinfo
) raises(SDLIPException);
};
};
Error conventions follow a subset of HTTP conventions: 4xx are errors in information supplied by the client. Error codes of the form 5xx signal problems at the server.
|
Code |
Error Name |
Meaning |
|
400 |
eInvalidRequest | Use if none of the more specific error codes fits |
|
401 |
eUnauthorized | Operation invocation may be correct, but it requires authorization |
|
402 |
ePaymentRequired | Client needs to supply payment |
|
404 |
eNotFound | The requested document is not served by this server |
|
405 |
eIllegalMethod | Specified operation is not part of SDLIP |
|
408 |
eRequestTimeout | Server has discarded state |
|
450 |
eQueryLanguageUnknown | Server does not support the specified query language |
|
451 |
eBadQuery | Query malformed |
|
452 |
eInvalidProperty | One or more specified document properties are not supported |
|
453 |
eInvalidSessionID | Session ID specified unknown to this server |
|
454 |
eInvalidSubcollection | Specified subcollection not supported on this server |
|
|
||
|
500 |
eServerError | Use if none of the more specific errors fits |
|
501 |
eNotImplemented | Operation is legal SDLIP, but server doesn't support it |
|
503 |
eServiceUnavailable | Service or requested subcollection is supported in principle, but is currently down |