 |
The Stanford WebBase Project
|
Our DLI2 WebBase project builds on our previous Google activity. It has the following goals:
- Provide a storage infrastructure for Web-like content
- Store a sizeable portion of the Web
- Enable researchers to easily build indexes of page features across large sets of pages
- Distribute Webbase content via multicast channels
Some of the challenges we are addressing include:
- The huge size of the information space
- Very large URL space
- Content size
- Limited resources
- Disk space
- Memory
- Time
- Bandwidth
- Web server tolerance
- Continuous update and maintenance
- Smart crawling to maximize freshness and likely relevance
- Crawler parallelism
- Crawling robustness; interruptible crawls
- Making it easy for researchers to use the facilities
- Standard access API
- API for building new indexes
- Convenient distribution of entire content
The project is developing the following facilities:
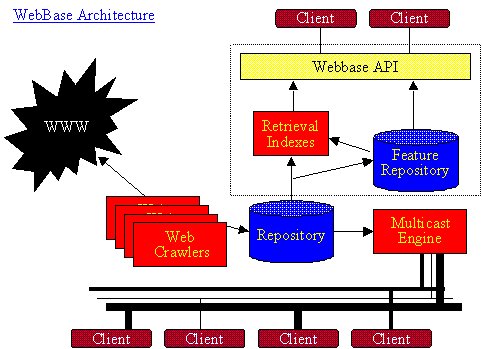
- Smart crawling technology. This will allow us to crawl 'valuable' sites more frequently or more deeply. The
measure of 'value' is, of course, itself an important research topic. Google's page rank is one such measure.
- Web repository. This infrastructure will hold large numbers of Web pages, and will allow experimental
search and analysis over that information. We are working on the following components:
- An archive to hold the (compressed) pages that our crawler acquires. This archive will enable
random access via an index. The archive is also capable of streaming its entire content to a client.
- An index factory. This facility will enable researchers to easily add novel indexes to the
Webbase. To use the index factory, the researcher implements a feature extraction engine. When presented with a
Web page, such an engine computes some page property of interest to the researcher. Examples: reading level, genre,
link property analyses... Once the engine is constructed, the researcher requests that the archive be 'streamed
past' the extraction engine. Based on the engine's output, the index factory will add an appropriate index to the
Webbase. This index will then be available to the community. Webbase will also keep the index up to date as the
archive is refreshed through new crawls.
- Wide-Area Web Data Distribution. Our distribution machinery will allow researchers everywhere
to take advantage of our collected data. Rather than forcing all index creation and data analysis to run at the
site where the data is located, our wide-area data distribution facility will multicast the archive's content through
multicast channels. Channels may vary in bandwidth and content. Subscribers specify the parameters of their channel.
See Junghoo Cho's Powerpoint presentation for more detail.