With the advent of the Web, information of broad interest has rapidly moved online.
The penetration of online information into the everyday lives of broad population sectors, as well as corporate
and military establishments, has revolutionized the way we approach information-related tasks. Both the production
and consumption of information is increasingly in the hands of nonspecialists who have generated a dazzling palette
of resources. Unfortunately, this very exciting development also produces the widely suffered problem of the Web:
information glut that often prevents the discovery of useful information, while overwhelming analyst resources
with irrelevant material..
The arsenal of defenses against this problem has mostly been stocked with techniques from the field of information
retrieval (IR). In contrast to database systems, IR systems were ready for dealing with the relative poverty of
structure prevalent on the Web. IR systems have always been geared towards unstructured text, while databases specialized
on structured information.
Most of the information retrieval systems common today perform searches by computing some similarity measure between
a given query and the content of a collection. These systems differ from each other mainly in how effectively they
compute that similarity. While sophisticated similarity-based techniques have fueled important progress for Web
search engines, they are increasingly being overwhelmed by the amount of information they are confronting. Apart
from sheer volume, one particularly vexing problem is that IR techniques only deal with text. More and more often,
important information is contained in applets or audio and video clips, or text is embedded in graphics, and is
therefore difficult to access. IR techniques fail in those cases.
The Value Filtering project at Stanford is working to address these problems. The project is developing searching
and filtering techniques that rely, in addition to textual similarity, on other information
value metrics. These metrics may be opinion
based, for example, did other colleagues we trust find a document useful,
or has this document been reviewed by some editorial board? The metrics may also be access-pattern
based, e.g., has this video been retrieved by many users? The metrics
may be context-based. For example,
is the information coming from a trustworthy source, do we know the author, or are the Web pages that point to
this document related to our search?
An early result of the Stanford Value Filtering project was the Google search engine, which has now been spun off to a company (http://www.google.com). This engine uses a Web spider to crawl millions of pages. The system stores information about all the links it encounters. During a search, the engine provides value filtering by ranking those documents high that have many other documents pointing to them. The Google engine thus views the Web as an information artifact that arose from humans pursuing their own interests. By analyzing the structure of the artifact, the engine deduces value information without requiring any specifically dedicated human effort. If many users found it in their interest to include links to some document, then that document is presumably important in some ways. By using a value filtering approach, Google in effect gets 'a free ride' in its analysis by drawing implicit value conclusions from user behavior.
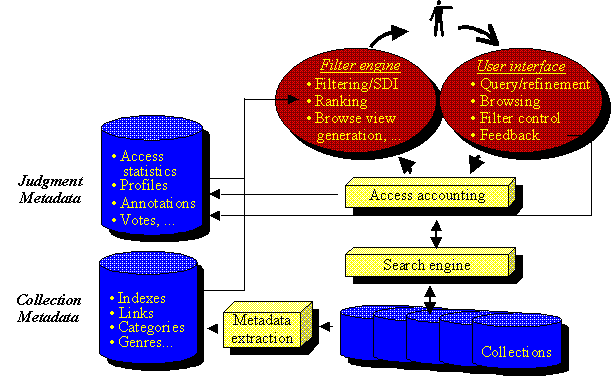
Link structure is not the only source of value information. Figure 1 shows a conceptual architecture that captures several more promising possibilities the project is exploring.
Figure 1: Conceptual Value Filtering Architecture
Beginning at the bottom of Figure 1, a metadata extraction module searches the collection(s) of interest for value information. In our Google example, the extraction consists of the crawler collecting the Web's link structure. Other kinds of metadata include information about the 'genres' of documents in the collection, special indexes, etc. This metadata is stored in the collection metadata on the left. Further up in Figure 1 we see an access accounting module which feeds access statistics to the judgment metadata store. In situations where user access to the collection can be observed, these statistics can provide important value information. The accounting module can derive user profiles, and popularity measures by observing where users search. One way to collect access information is to provide a service to users that is combined with the access module, and is valuable enough that users want to access the collection through that service. For example, Alexa has experimented with providing users real-time indicators of link popularity on each page they browse. For each page, the user gets an indication of how popular each of the page's outgoing links has been in the past, when other users visited the same page. In order to enjoy this service, users must browse the Web under the auspices of an Alexa software module. In addition to providing the service, that module also collects access information.
Along similar lines, the Stanford Value Filtering project plans a service that allows users to annotate Web pages, without needing to physically modify those pages. The annotations might be reminders users leave for themselves, or they might be directed at colleagues who are known to be scanning the same information space. The annotations themselves can be useful value information, as are the collected access paths.
Completing the tour of Figure 1, we see the two user modules at the top. The left oval represents the output module that displays information to the end user. It includes provisions for ranking the output, for filtering, and for generating specialized views. The oval on the right represents user input. This input includes the act of browsing itself, as well as active control of the system's filters, and the ability to provide feedback by voting or other means.
In support for its value filtering efforts, the project has been constructing a value filtering testbed. It includes a set of smart crawlers, a very large database of Web pages, an indexing engine, and the ability to disseminate the stored Web pages very quickly to clients on the Internet. The testbed's architecture is shown in Figure 2.
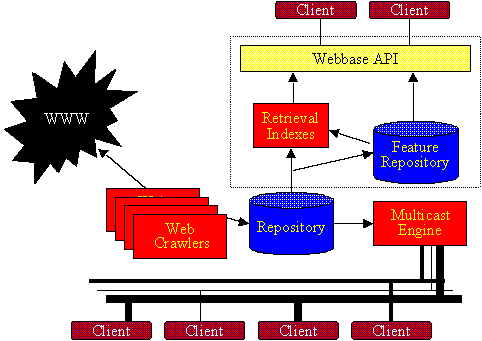
Figure 2: Architecture of Value Filtering Testbed
The clients at the top of Figure 2 are browsers and search interfaces for exploring the repository of Web pages that were amassed by the crawlers. Retrieval indexes aid in searching. The feature repository stores value or other intelligence information about pages in the repository. This intelligence is itself searchable, or it may be used for filtering information that flows up to the browser clients. The multicast engine enables us to 'pump' all of the crawled pages across the Internet to clients gathering value information or other intelligence about the pages (bottom of Figure 2). This multicasting engine enables these clients to perform their tasks without needing to go through the slow and error-prone process of crawling. The value information gathered by the clients can be fed back to the feature repository for storage. The testbed thus enables the collaborative collection of value information at a large scale.
Value-based information filtering is a key capability, without which search facilities for Web-sized repositories will collapse. The Stanford Value Filtering project is researching the collection and use of value information at a scale of millions of pages. First experiments, such as Google, have shown that value filtering techniques can be highly effective in finding truly relevant information.