
Gary Wesley (Bluegee gmail)
Updated October 2013
If you decide to use the data, please email Gary (
Jeez cs stanford Edu) for our funding
requests.
We would also appreciate knowing of any papers
that
come
out of your usage.
Make
sure the library path includes W3C's
libwww .
This library must be installed by a system administrator
with
root
privileges.
Make
sure environment variable WEBBASE points to
WebBase:
setenv WEBBASE [absolute path]/WebBase
(1) Run GNU make:
WebBase/> ./configure
WebBase/> make client
If you get:
handlers/extract-hosts.h:27:21: WWWCore.h: No such file or directory
handlers/extract-hosts.h:28:21: HTParse.h: No such file or directory
Your include path may be wrong:To use later gcc versions:
We expect it to be in /usr/local/include/w3c-libwww/WWWCore.h,
so you may need to change this in Makefile.in and configure.
(Order MAY matter)
Rerun ./configure.
Now try the network version:
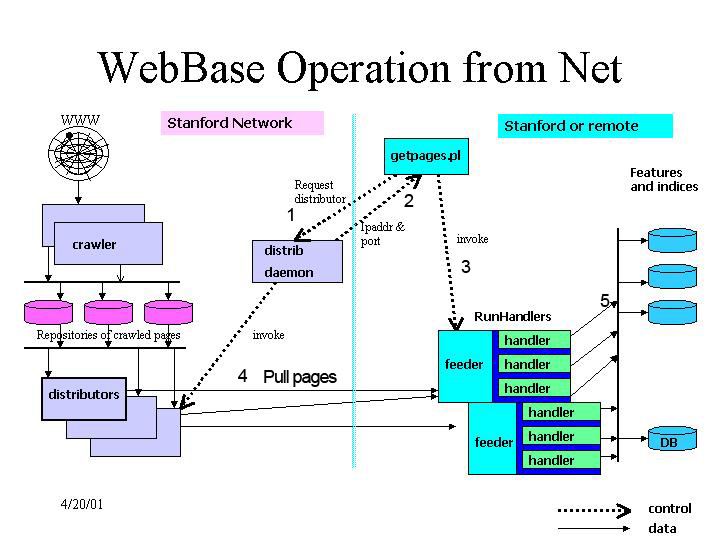
Method
1:
Run scripts/distribrequestor.pl to start a
distributor:
(either chmod +x scripts/*.pl or
invoke it with "perl")
args: (must be in this order)
# host
# port
# num pages
# starting web site (optional) e.g. www.ibm.com
# ending web site (optional)
# offset in bytes within web site (optional)
[example run:]distrib daemon returned 171.64.75.151 7160
WebBase/scripts> distribrequestor.pl wb1 7008 100
WebBase/scripts>Now you can invoke RunHandlers with the above info:
WebBase/scripts> ../bin/RunHandlers ../inputs/webbase.conf "net://171.64.75.151:7160/?numPages=100"will print back 100 sample pages. All instances of RunHandlers connected to
Method
2:
You can also use our one-step script getpages.pl
(no need to specify a first site )
(either chmod +x scripts/*.pl or
invoke it with "perl")
[example run:]
args: (must be in this order)Starting getpages.pl using Perl 5.6.0
# num pages
# host
# port
# starting web site (optional) e.g. www.ibm.com
# ending web site (optional)
# offset in bytes within web site (optional)
WebBase/scripts> getpages.pl 2 wb1 7008 www.ibm.com www.ibm.com (only give me www.ibm.com)
To
get all of the page, set CAT_ON = 1 in the
inputs/*.conf.
If
you get the ERROR:
bin/RunHandlers: error while loading shared libraries: libwwwcore.so.0:
cannot open shared object file: No such file or directory
you don't have your paths set right.
setting a variable called LD_LIBRARY_PATH where you're about to run the
WebBase client. For example, if you found your libwwwcore.so in
your
/opt/somewhere/lib/libwwwcore.so, then you could tell your system:
setenv LD_LIBRARY_PATH /opt/somewhere/lib
Return
codes:
contact us to report these:
blank
page means there is no server running on that
port
If you get a line of just numbers and not much else:
256 means I have a distributor running on a server with no data or a
dangling
softlink
32512 is usually a missing softlink on the server
( fix is ln -s /u/gary/WebBase.centos/bin/runhandlers
/lfs/1/tmp/webbase/runhandlers )
or it is missing shared libraries: libwwwutils.so.0
Note on the output:
This
next line is just a separator, so that
RunHandler
knows
it is getting a new page:
==P=>>>>=i===<<<<=T===>=A===<=!Jung[...]
--
page separator
URL: http://www.powa.org/ -- page URL
Date: June 3,
2004
-- when crawled
Position:
695
-- bytes into the site so far
DocId:
1
-- sequential page id within site
HTTP/1.1 200
OK
-- response to our http request
Death
threat:
If a distributor is inactive for a while,
it may be
killed by us so that we can reuse the resources.
To restart at the same point you must start a new
distributor
@ the offset where it left off
( + 1 to prevent getting the previous page again).
Putting
out a contract:
If you are done, you can run distribrelease.pl
[remote-host] [host port] [stream port]
from the same machine you requested on. We will
immediately
kill the
distributor for you.
We especially recommend this if
you are running
many requests in 1 day so that we do not run out of
resources.
If
you specify firstSite/lastSite, please note that
you
can only use the root
(e.g. www.ibm.com) not a page within the site
(e.g.
01net.com/envoyerArticle/1
)
and dont include the http:// part.
-------------------------------------------------------------------
To create a new webpage stream handler:
You
can use the other handlers in the distribution
as
templates.
To add a new handler, add the following to the
appropriate
places:
* 1) #include "myhandler.h" into
handlers/all_handlers.h
* 2) handler.push_back(new MyHandler()); into
handlers/all_handlers.h
(following
the template of the handlers already there)
* 3) in Makefile, add entries for your segments
to compile
in the
line: HANDLER_OBJS = jhandler.o [...]
*opt)in Makefile, customize your build if
necessary
by adding a line
jhandler_CXXFLAGS = -Iyour-include-dir --your-switches [...]
(following the template of the handlers already there)
We
also have a one-button script called
scripts/addHandler.pl
that will
prompt you for all your pieces and put them in place,
without you having
to do the above file surgery yourself.
WebVac - the WebBase web crawler or spider. Used to be
called Pita.
RunHandlers
- (formerly "process") an executable
that
indexes a stream,
file or repository.
Made up basically of a feeder and one or more handlers.
handler
- the interface that any index-building
piece
of code must implement.
The interface's main (only) method will provide a page and
associated
metadata and the implementor of the method can do whatever he wants
with it.
feeder
- the interface for receiving a
page
stream
from any kind of source
(directly from the repository, via Webcat, via network, etc.). The
key method of the interface is "next" which advances the stream by one
page. After calling next, various other methods can be used to get the
associated metadata for the current page in the stream. Can also be used
to build indexes if the index-building code is written to process page
streams
distributor
- a program that disseminates
pages to
multiple
clients
over the network, supporting session ID's, etc... a generalization
of what
Distributor.cc
in Text -index/ does.
offset
- used in distributor requests to specify how
many bytes to start from
the
beginning of the site.
DocId
- DocId is computed within the
download.
If you download any portion of the crawl,
even from the middle,
it will begin with 0.
If you download all the crawl,
it will be monotonically increasing
from start to end.
